
目录
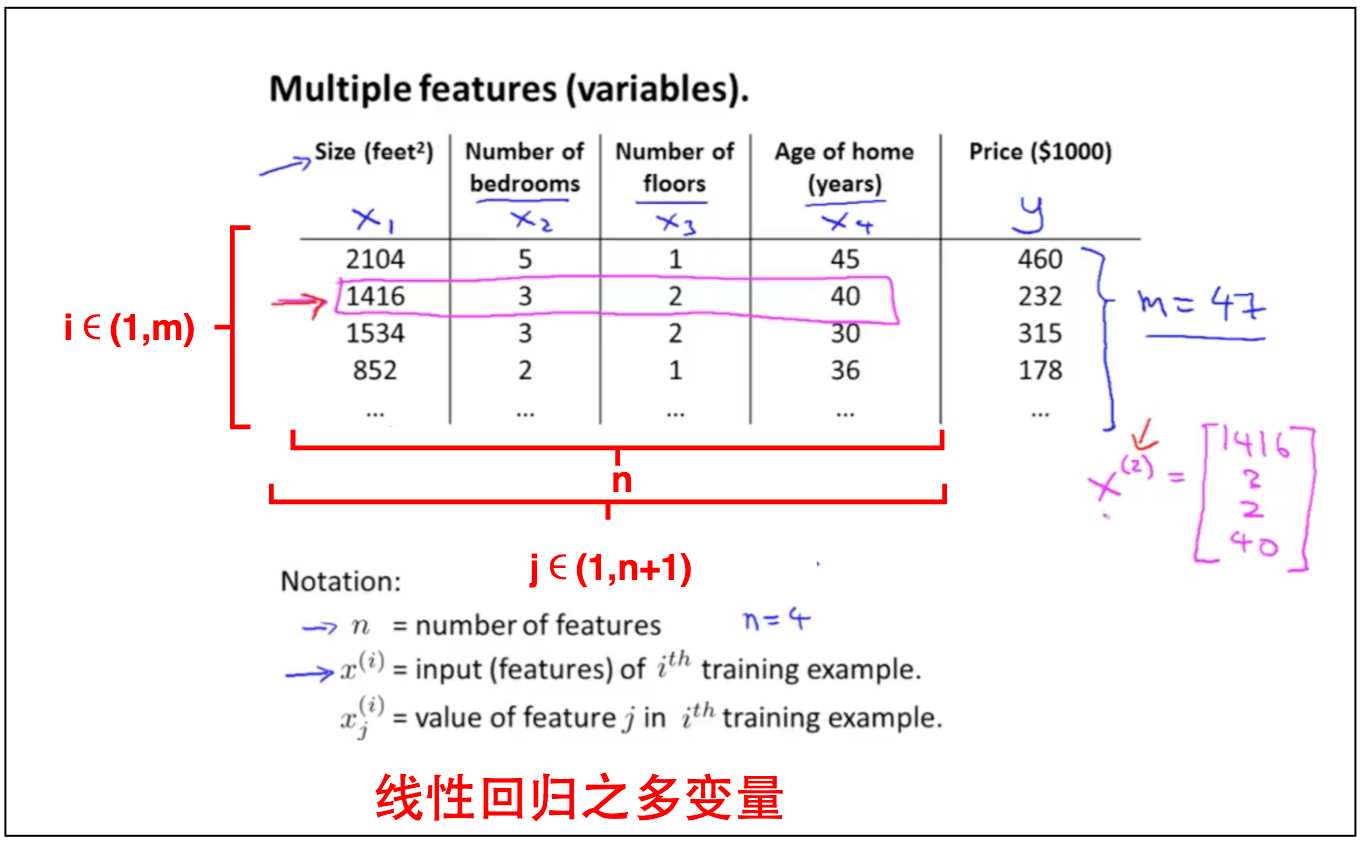
1 线性回归之多变量介绍
上篇笔记中我们介绍了线性回归之单变量,即输入变量为一个$x_1$。这篇笔记我们输入变量的个数延伸为任意多个,即$x_1,x_2,…,x_n$,该模型更能准确描述现实生活中的问题,且线性回归之单变量是线性回归之多变量的退化情况。
2 线性回归之多变量详解
2.1 预测函数
线性回归之多变量的预测函数如下:
将其向量化(Vectorization)用矩阵表示为:
where $x_0^i = 1 \;for \; (i\in1,\cdots,m)$
2.2 成本函数
线性回归之多变量的成本函数和线性回归之单变量一样。
2.3 寻找最优值
2.3.1 梯度下降
$for \; (j\in1,\cdots,n+1)$repreat until convergence:
展开即$for \; (j\in1,\cdots,n+1)$(其中n是多变量的维度+1,即上图中的col feature维度+1;m是数据的维度,即上图中的row维度)
2.3.2 代数解
2.4 实际情况
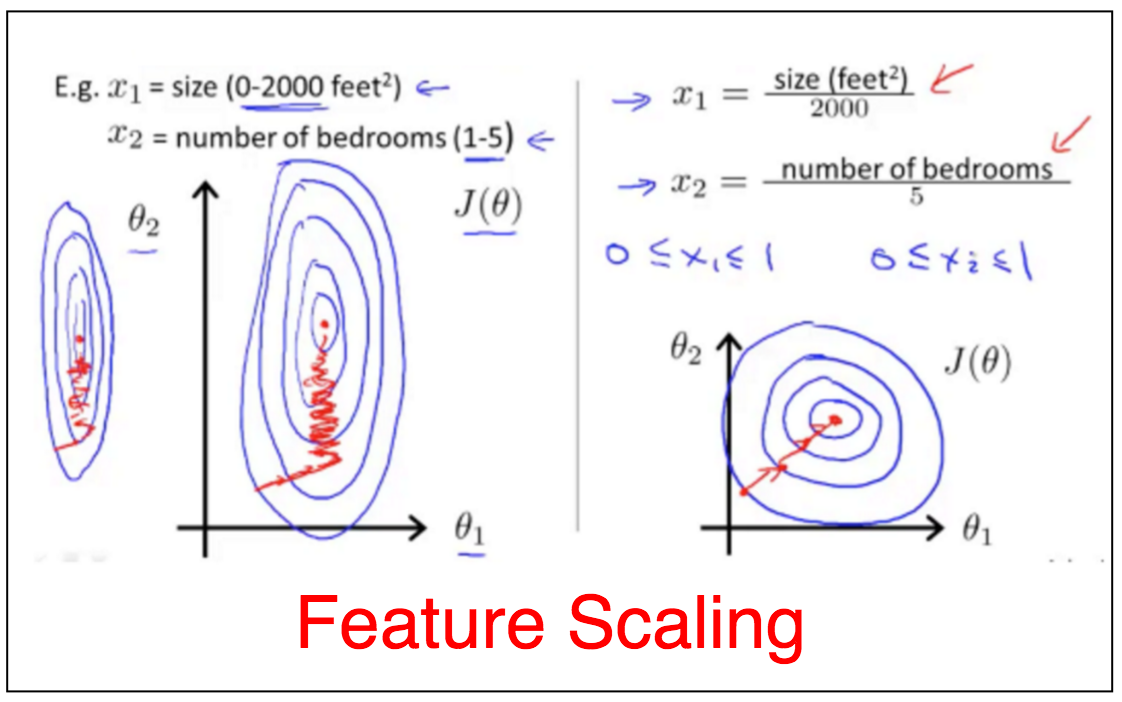
2.4.1 Feature Scaling
所有的变量在一个scale上可以确保梯度下降可以快速找到最优值。
将所有输入变量x转换成如下形式:
where $\mu_i$是所有$x_i$的平均值,${S_i}$是$x_i$的最大最小值之差。
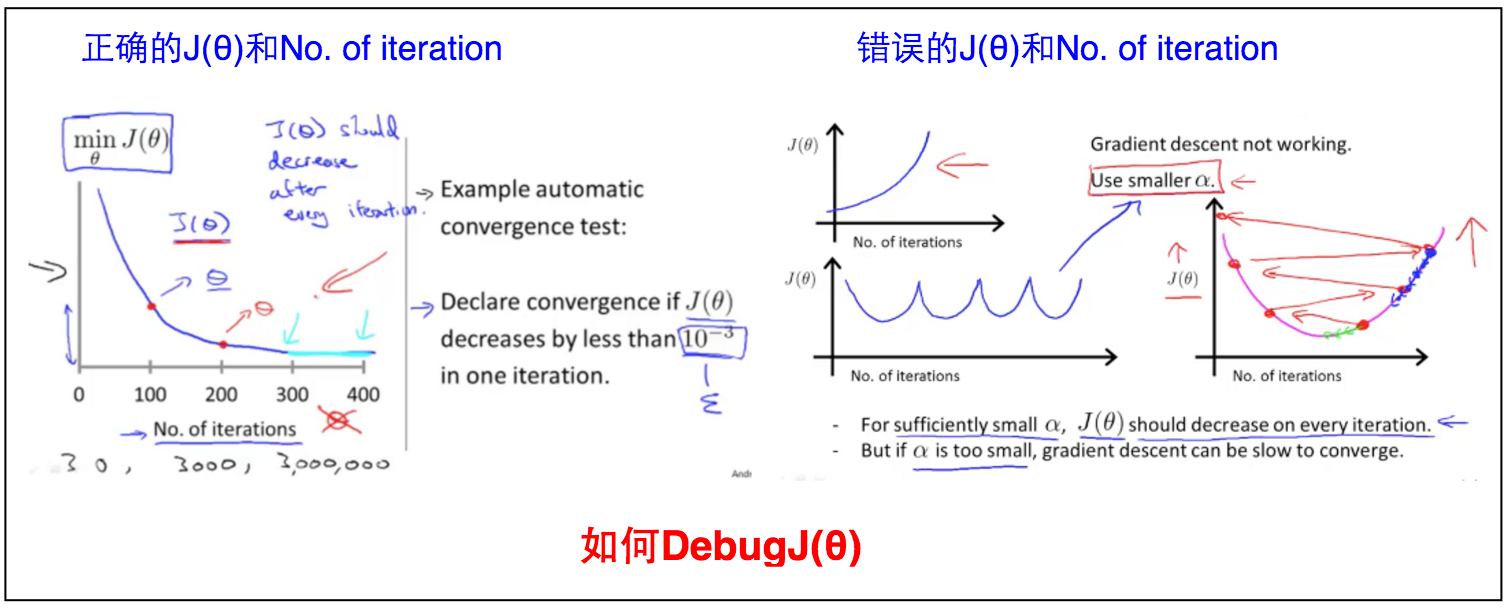
2.4.2 Learning Rate
如何确定梯度下降程序运行正确。主要看$J_\theta$和No. of iteration的关系。
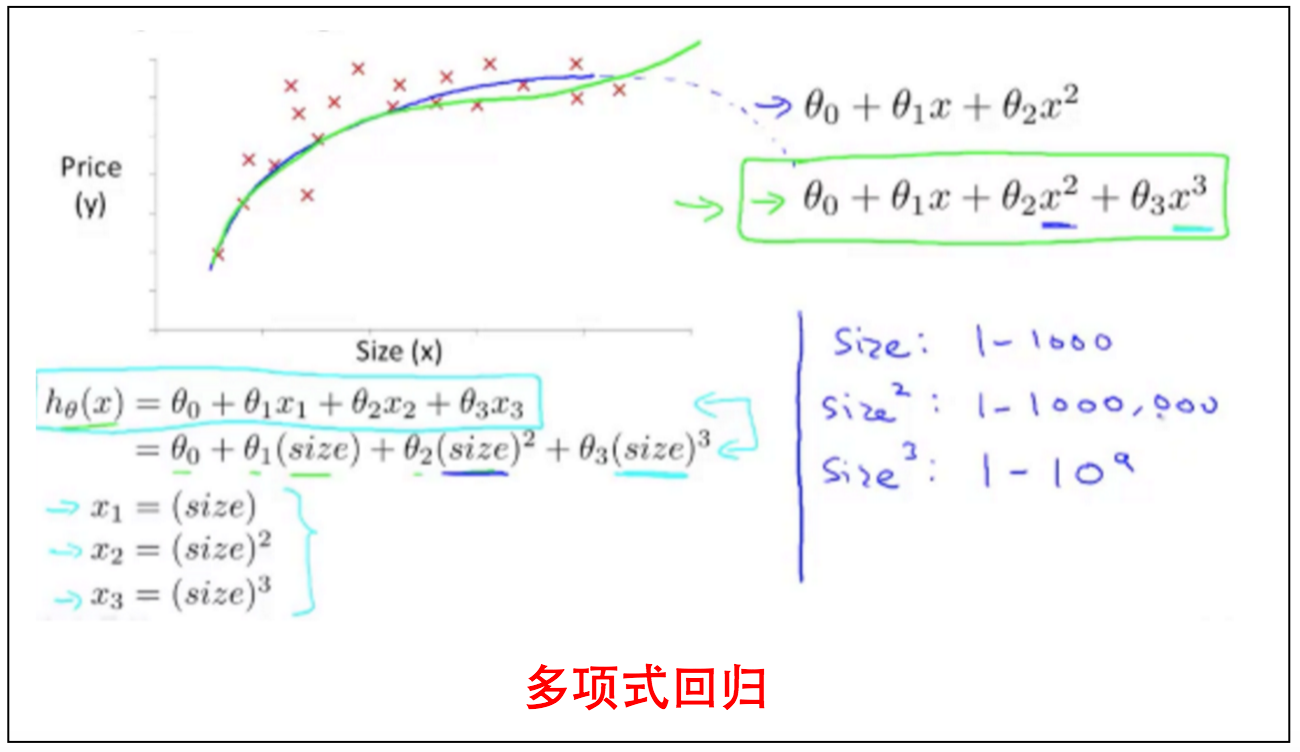
2.5 多项式回归
在线性回归之单变量和线性回归之多变量之间有一种转换情况,即线性回归之单变量不能很好拟合数据,这个时候就需要用单变量的多项式来通过线性回归之伪多变量来拟合,例如下图,单独size一个变量的线性拟合不能准确描述价格的变化,因此用size的多项式通过 线性回归之多变量来拟合。由于$size$,$size^2$,$size^3$的scale不在同一个数量级上,因此需要通过Feature Scaling来优化。
2.6 Normal Equation
除了用梯度下降来接近$minJ_(\theta)$,还可以通过代数方法求导获得。
for every $j$, solve for $\theta_0,\theta_1,\cdots,\theta_j$
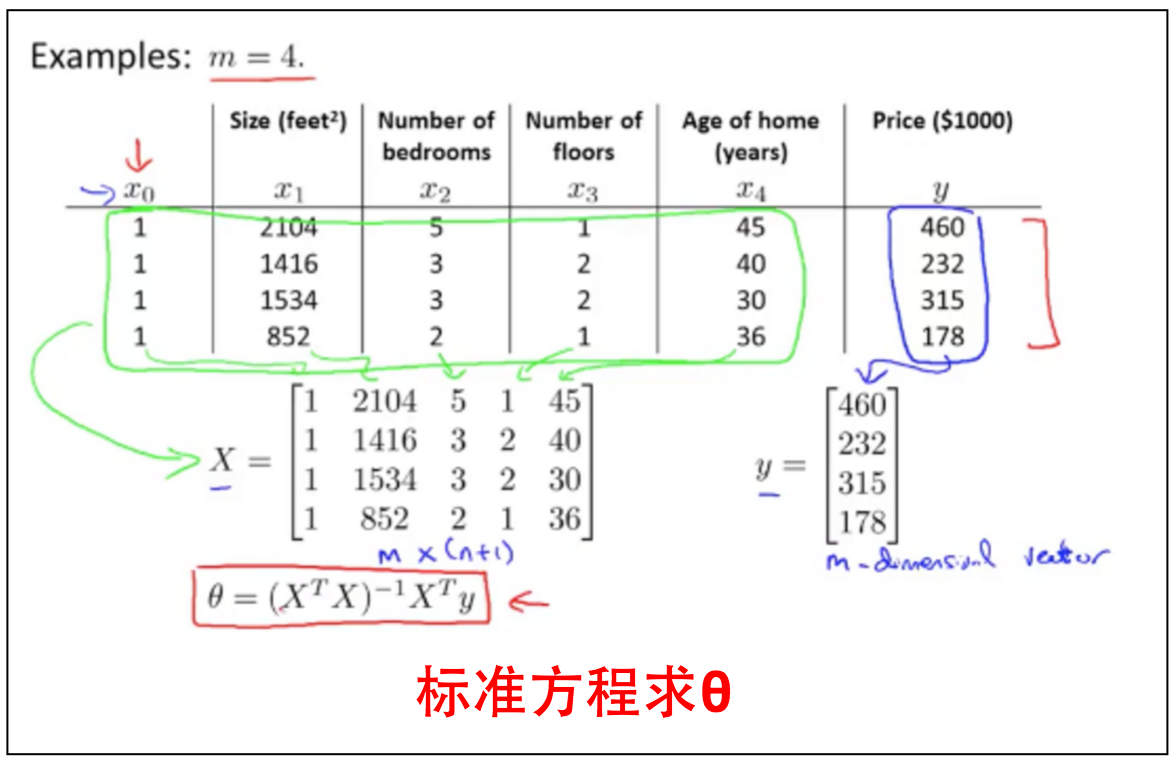
梯度下降和标准方程都是两个求解$\theta$来获取最低$J(\theta)$的方法,但是两者各有优缺点,见下图。

3 Matlab and Octave 入门
见这里。
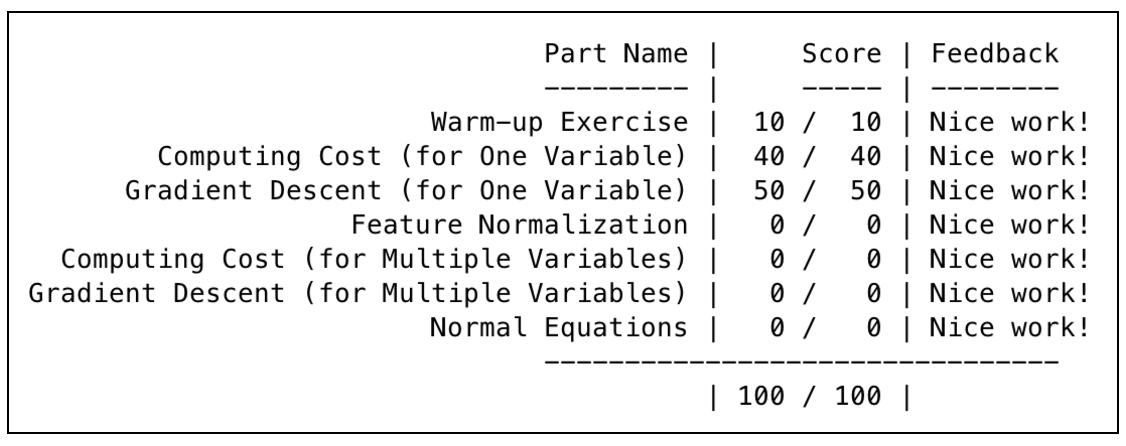
4 作业
附上一张跑分图。
5 总结
本文将线性回归之单变量泛化成线性回归之多变量的情况,并且对其预测函数,成本函数,以及如何获取最低成本值的方法(梯度下降,标准方程)进行讲解。在实际过程中,可以通过Feature Scaling来加速学习速率;并且通过$J_\theta$和No. of iteration的关系来debug程序是否正确(正确的程序每多一步,都会降低$J_\theta$)。其中单变量如果线性回归不准确,可以将其转换成多项式再通过线性回归之多变量和Feature Scaling来求解。
