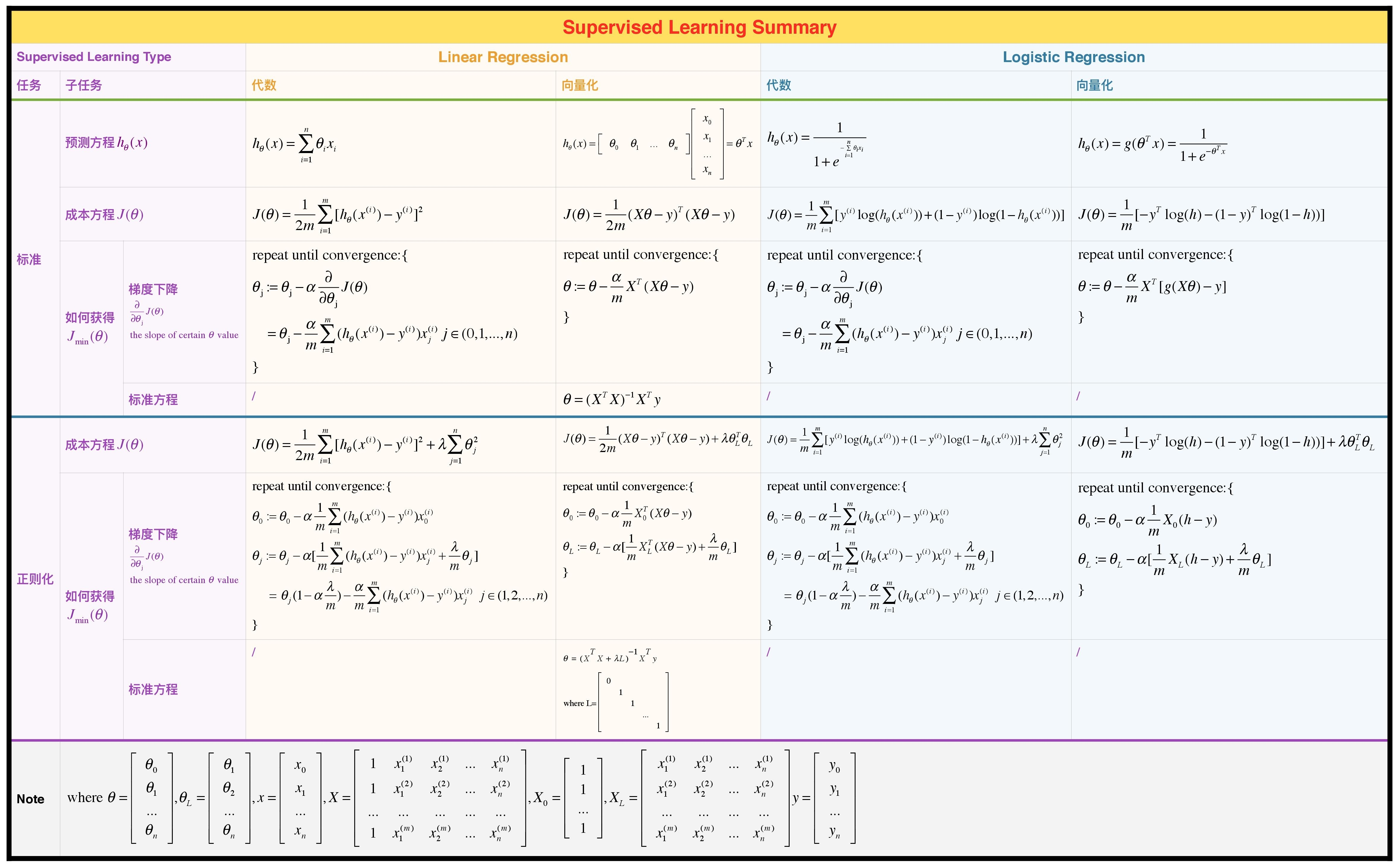
目录
1 Logistic Regression介绍
现在我们从回归问题转到分类问题。别被Logistic Regression这个词迷惑了(之所以叫这个名字是由于历史问题,见这里),它是分类问题,而不是回归问题。
2 Logistic Regression详解
不像输出y是一个连续的函数,Logistic Regression的输出是离散数据,即$y\in \lbrace 0,1, \cdots, n \rbrace $。
2.1 二分类
我们现在首先考虑最简单的情况,即即$y\in \lbrace 0,1 \rbrace $。我们称之为二分类问题。
有人会说这好办,我们只要给原来的线性回归的输出map到一个$\lbrace 0,1, \cdots, n \rbrace$值即可,需要做的是找一个map的边界。但是这会过度简化模型导致输出不准确,请看下图例子。
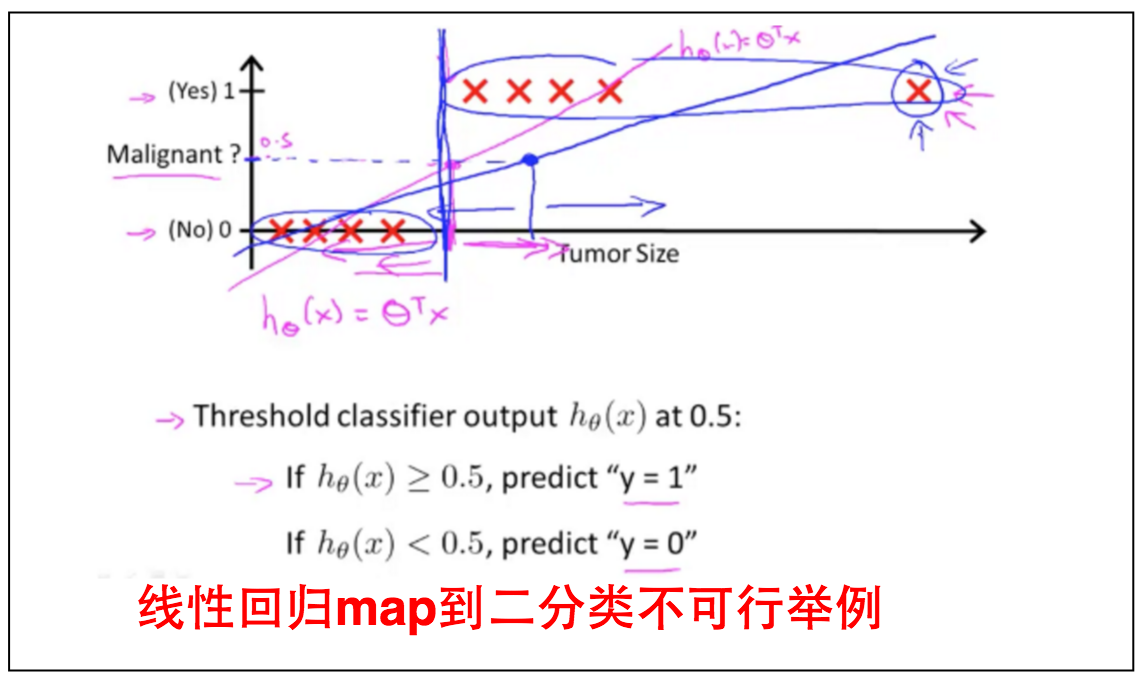
新加一对Training Data就会使得原来的预测函数不准确。
那么该如何确定预测函数的形式呢,请往下接着看。
2.1.1 预测函数
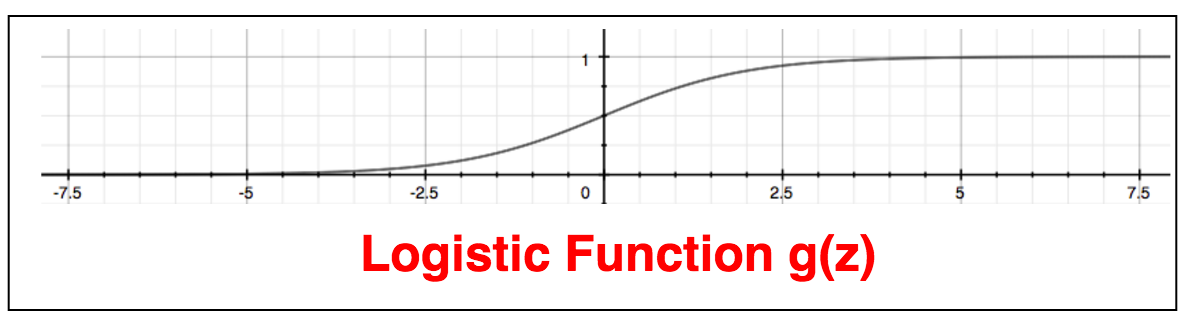
其中$g(z)$的图形如下所示,其将任何实数转换成$\lbrace 0,1\rbrace$之间的值。g(z)被称之为双弯曲函数(Sigmoid Function)或者逻辑函数(Logistic Function)。
我们将线性回归的预测函数$h_\theta(x)$代入到$z$:
那么该如何解读$h_\theta(x)$的函数呢?如果$h_\theta(x)=0.7=70\%$,就意味着有$70\%$的概率我们的输出是1,即:
那么我们来看下决定边界(Decision Bouhdary):
决定边界(Decision Bouhdary):是分开$y=0$和$y=1$的边界。
例如:
当 $y=1$,即:
在这个例子中,决定边界是$x_1=5$的直线,直线左边是$y=1$,右边是$y=0$。 当然决定边界不一定是直线,也可以是二次曲线,比如圆,抛物线等。
2.1.2 成本函数
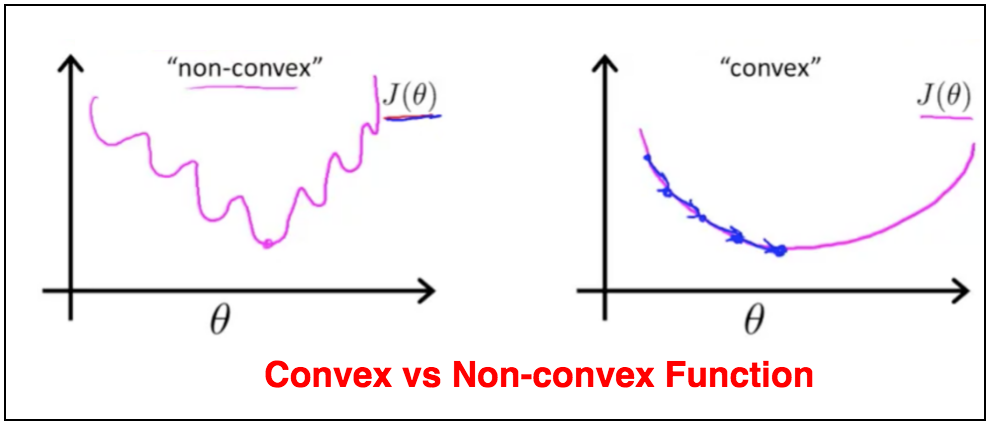
如果我们用同样的线性回归的成本函数来描述分类问题,会导致成本函数有很多局部最低点。换句话说,该成本函数将不是一个凸函数(Convext Function),,如下图
Convex vs Non-convex Function
2.1.2.1 复杂成本函数
我们将成本函数重新表示成下面形式。
对于线性回归,
对于分类,
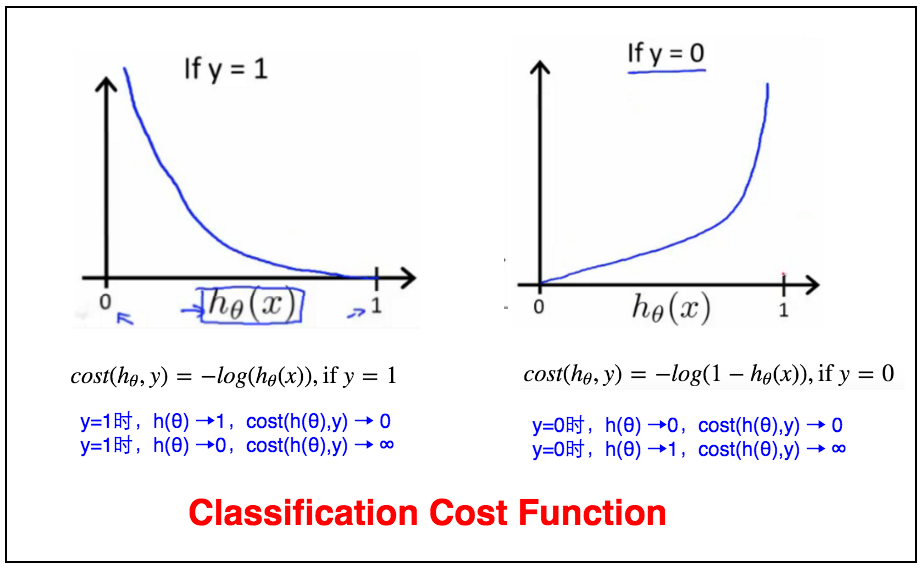
2.1.2.2 简单成本函数
我们可以将上面复杂成本函数简化成下面简单成本函数的形式, 即$y=0$和$y=1$和复杂成本函数一样。
2.1.3 梯度下降
分类结合梯度下降算法如下:
2.1.4 高级优化
除了梯度下降算法外,还有其他算法可以让我们逐步接近$J_{min}(\theta)$,比如下面这三种方法:
这三种方法比梯度下降的优势是可以更快接近$J_{min}(\theta)$且不需要人工选择$\alpha$的值;缺点是实现起来稍显复杂。我们如果要用,可以直接用octave或matlab里的库。
下面是matlab和Octave的fminunc函数,用于计算局部最小值。
fminunc函数:第一个参数是需要计算局部最小值的函数$J$,第二个参数是初始的该函数值$θ$,第三个函数是$options$(梯度开启,最多循环次数)。其中函数$J$返回函数值和梯度。

2.2 多分类
二分类的问题比较简单,但是对于结果是多种类的多分类问题,我们该如何处理呢?比如天气的分类是Sunny,Cloudy,Rainny,Snowy等。
多分类:可以简化成二分类。
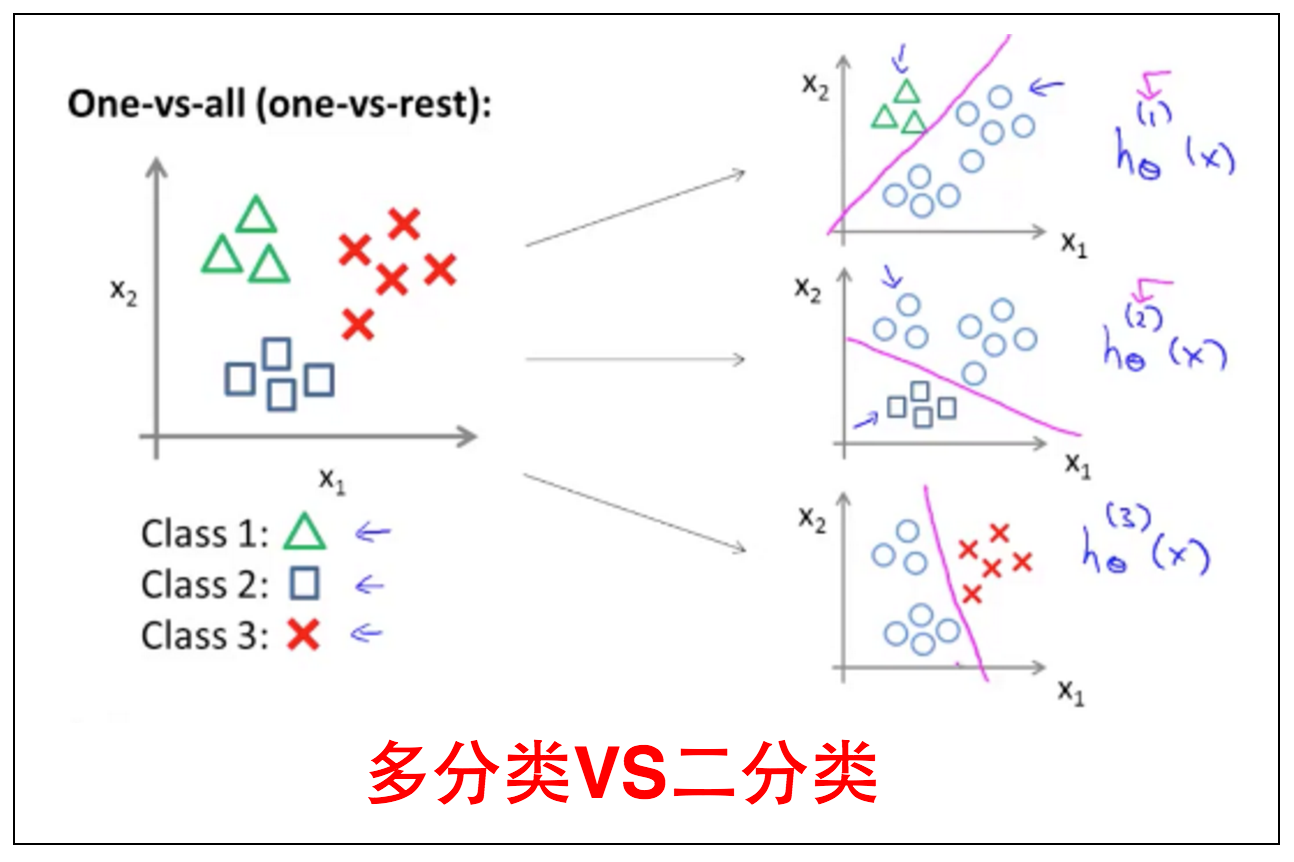
多分类的问题可以简化成多个二分类问题,如上图所示。用$y=0$(该类)和$y=1$(非该类)应用到每一个class上,分别求出他们的预测函数。
3 正则化
3.1 拟合问题
在监督式学习的回归和分类中,都会碰到Under Fitting (High Bias,太少Feature)和Over Fitting (High Variance,太多Feature)的问题,见下图。
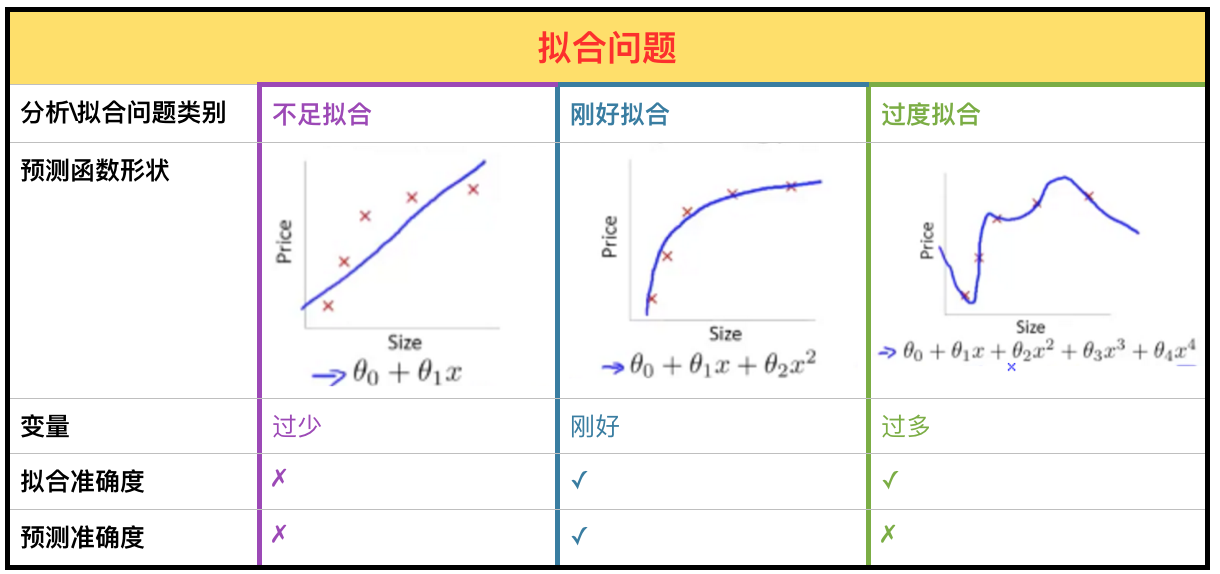
过度拟合(Over Fitting):使用了过多的参数,虽然完美地拟合到已有数据,但是对于未来的预测不准确。
通常来说有两种解决过度拟合(Over Fitting)的方法:
-
减少Feature数量,通过人工筛选或者筛选算法(后面的笔记会介绍);
-
正则化(Regularization),保持所有Feature,但是减小Feature的权重,即$\theta_(j)$。这当我们有很多略有用的Feature时解决的效果很好。
3.2 成本函数
那么如何应用正则化,它对原来的cost fucntion$J_{\theta}$的影响又是什么呢,我们可以从下面这个例子来用直觉理解。
当预测函数是4个Feature时,如果给成本函数加上$1000\theta^3+1000\theta^4$,可以看到为了使$J_{\theta}$为0,$\theta_3$和$\theta_4$必须要比原来没有这两项要小得多,从而降低$\theta_3$和$\theta_4$的权重。
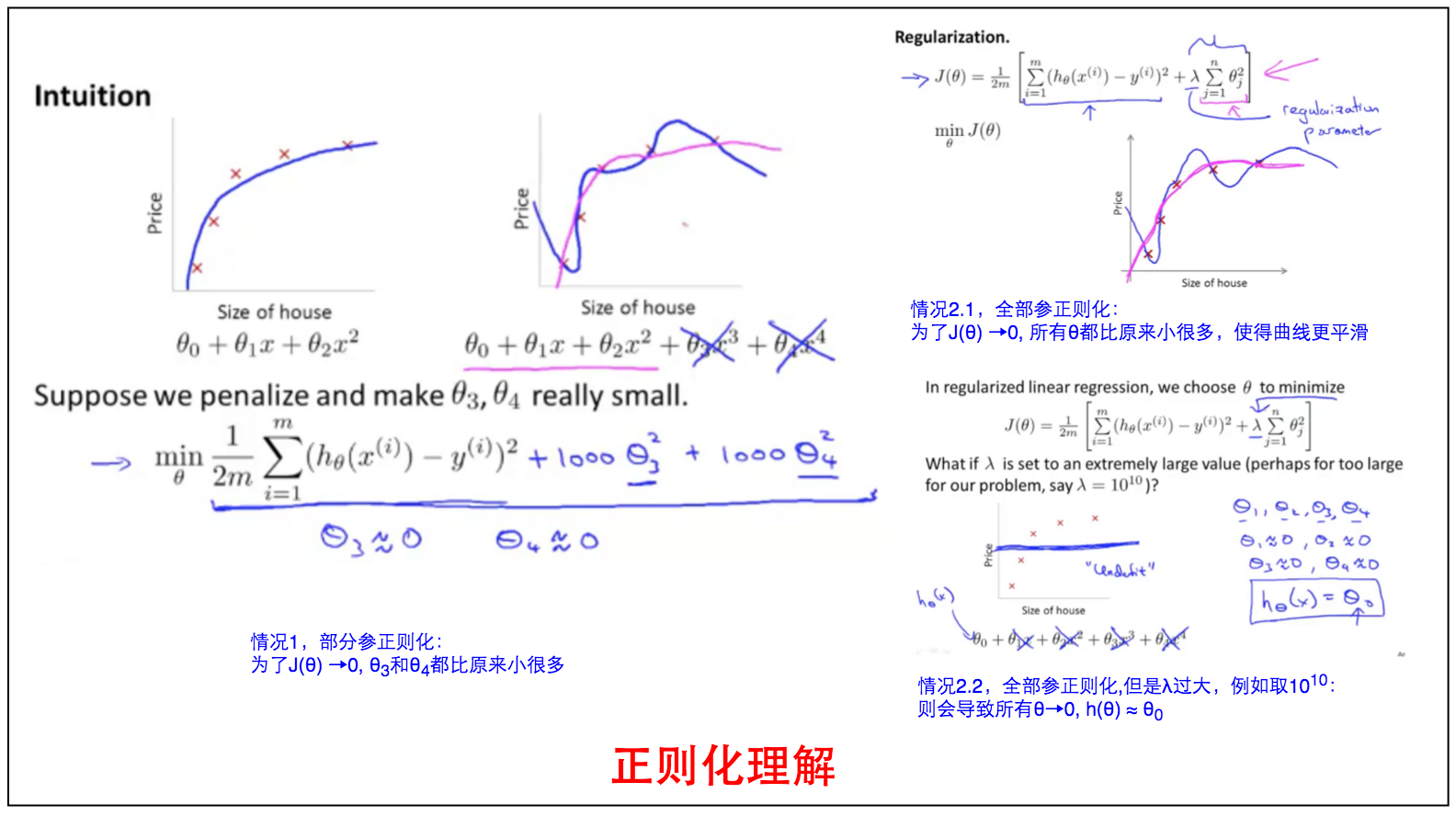
有时候我们为了让预测函数更平滑,给所有的Feature都加上这么一项,即:
但是若$\lambda$取值过大,有可能会将过度拟合削弱为刚好拟合并且进一步变成不足拟合,导致$h_\theta(x)= \theta_0$,而其他$\theta_i≈0$。
3.3 正则化应用
3.3.1 正则化线性回归
3.3.1.1 梯度下降
如何理解上面的方程呢。在任何情况下$(1-\alpha \frac \lambda m)<1$都成立,直觉上可以理解为正则化的$\lambda$使得每一步的$\theta_j$在一次更新过程中都相应地减小为原来的$(1-\alpha \frac \lambda m)$。
##需要注意的是$theta_0$不能同时被正则化,否则所有$theta$都被正则化就相当于没有正则化。##
3.3.1.2 标准方程
我们在第二篇笔记中提到过可以由标准方程来求出预测函数,即:
但是有两种情况下$(X^TX)$是退化矩阵(不可逆的),1是$m≤n$,2是$n$有重复(比如一个是面积 in $m^2$,一个是 in $feet^2$)。但是正则化可以让第一种$m≤n$退化矩阵变为可逆矩阵,如下:
3.3.2 正则化逻辑回归
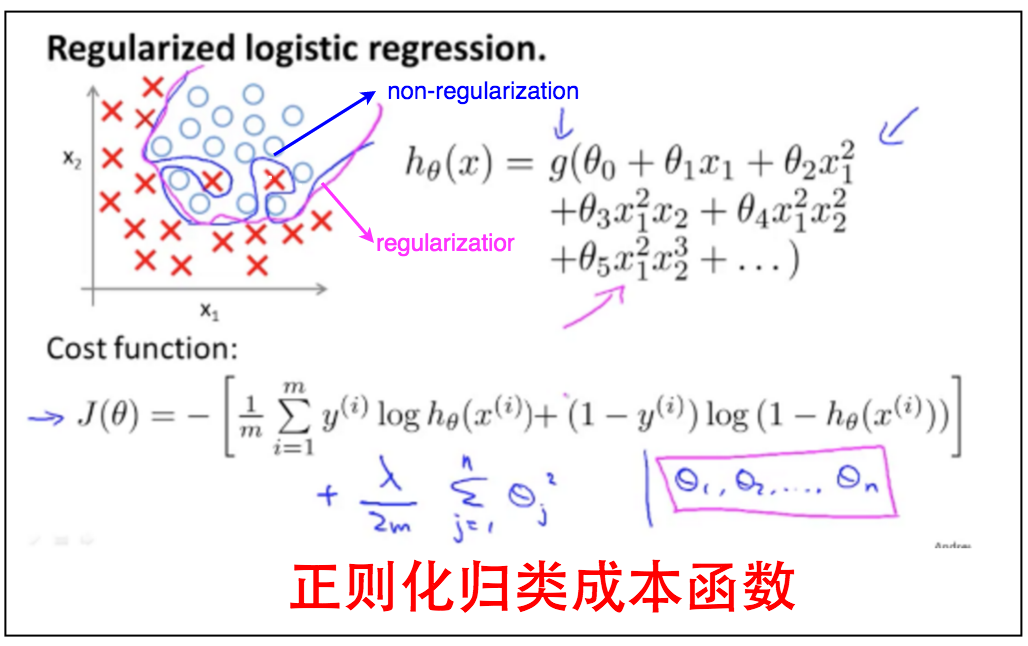
3.3.2.1 梯度下降
和回归一样。
4 作业
附上一张跑分图。
5 总结