
目录
1 Machine Learning 介绍
1.1 What is Machine Learning
Machine Learning:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by p, improves with experience E. by Tom Mitchell.
Example: playing checkers.
E = the experience of playing many games of checkers;
T = the task of playing checkers;
P = the probability that the program will win the next game.
机器学习的现代严格定义如上,一个更让人容易理解的定义是不通过显性的编程来给予电脑学习的能力。
通常来说,任何的机器学习都可以归为下面两类:
-
监督式学习(supervised learning);
-
非监督式学习(unsupervised learning);
1.2 Supervised Learning
监督式学习(supervised learning):可以由已有的输入输出映射建立一个函数,用以在新的输入数据上,推测输出数据。监督指的是提供了已有的输入输出映射。
监督式学习(supervised learning)通常分为下面两类:
-
回归(regression):预测函数的输出是连续。比如在给定男性脸部图片和年龄的映射基础上,给定一个男性的脸部图片,推测其年龄。
-
分类(classification):预测函数输出是离散。比如在给定男性脸部图片和年级的映射基础上,给定一个男性的脸部图片,推测其是读小学,中学还是大学。
1.3 Unsupervised Learning
非监督式学习(unsupervised learning):将一簇输入数据(无输出数据)根据其特点分类。非监督指的是没有提供输入输出映射。与监督式学习的分类不同的是即没有输入输出映射,又不知道输出具体是哪几类。比如在给定男性脸部图片的数据基础上,将其分类(分类依据可以由用户设定,比如肤色)。
2 线性回归之单变量
单变量线性回归是监督式学习回归的一种最简单问题。它利用单一变量(即只有一个输入变量x)和其映射的输出,来获取预测函数,使得给定一个变量,能获得最准确的输出。
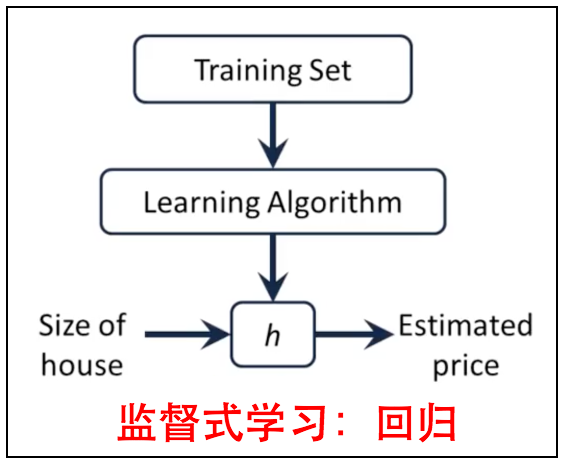
2.1 预测函数
它的数学模型如下:
2.2 成本函数
我们可以测试预测函数的准确性,用方差来表示,称其为成本函数$J(\theta)$:
其中$\frac 1 2$表示一个特殊系数,$\frac 1 m$表示平均到每一对数据,$(h_\theta(x^{(i)})-y^{(i)})^2$表示预测函数的$y^{(i)}$和实际的$y^{(i)}$的差距。因此我们需要找到一对$\theta_0$和$\theta_1$使得$J(\theta)$最小。
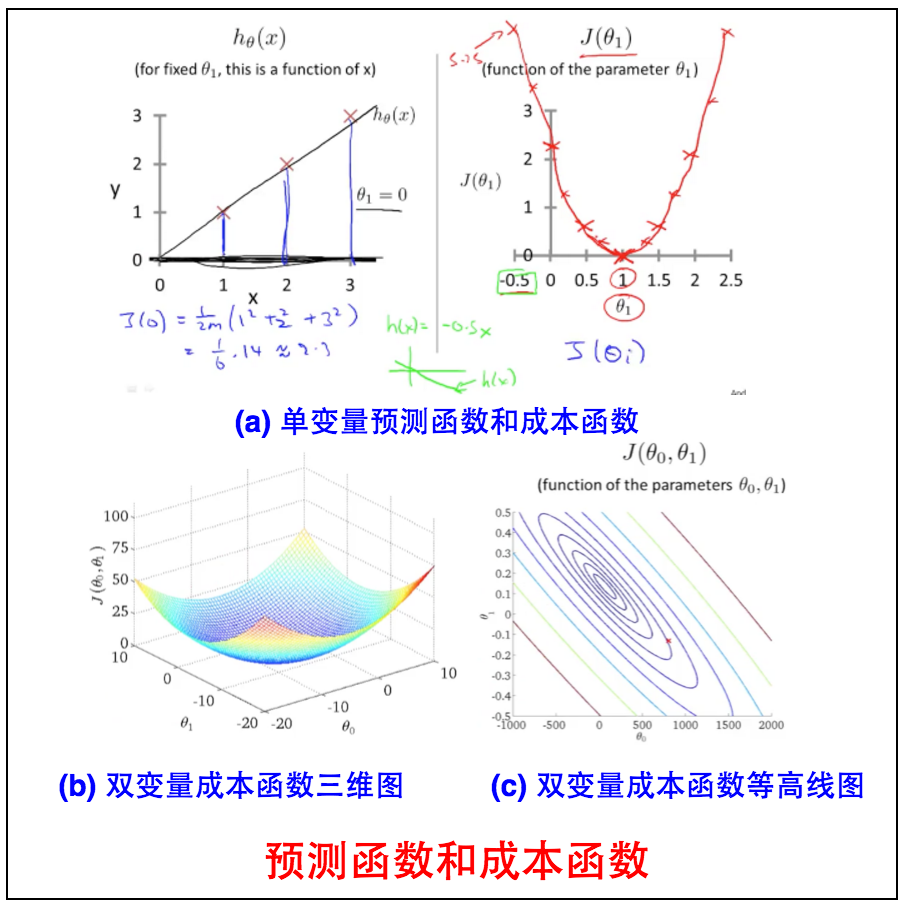
2.3 预测函数和成本函数的关系
我们可以根据预测函数$h_\theta(x_i)$来算出其成本函数$J(\theta)$。$\theta_0=0$时的单一变量预测函数和成本函数关系如下图a,可以看到当$\theta=1$时,$J(\theta)_{min}=0$为最小值。当有两个变量 $\theta_0$和$\theta_1$时,需要用图b三维函数或者图c等高线来表示,可以看到这是一个convex函数,只有一个全局最小值(global minimium)。
3 梯度下降
3.1 梯度下降介绍
现在我们有了预测函数以及成本函数(用来测试预测函数有多准确描述已有数据),下一步是如何自动提高预测函数,这个时候我们就要用到梯度下降(gradient descent)算法。
where j=0,1 represents the feature index number. Intuivitly, this could be thought as:
repeat until convergence:
对于$\alpha$的讨论有以下几点需要注意:
-
$\alpha$称之为步长,太小,使得每一次$\theta_j$的更新步长太慢;太大,有可能错过$J(\theta)_{min}$;
-
当$\theta_j$越来越接近最优值时,$\alpha \frac\partial {\partial \theta_j} J(\theta_0,\theta_1)$越来越小(因为$\frac\partial {\partial \theta_j} J(\theta_0,\theta_1)$越来越接近0)。因此我们不需要自己人工改变$\theta_j$值,只需要取一个适当大小的$\alpha$,然后通过梯度下降去自动接近最小值。
3.2 线性回归和梯度下降
当将成本函数$J(\theta)$代入到上面方程可得:
repeat until convergence:
梯度下降算法的意义在于我们只需要猜测一个预测函数的起始点$h(\theta_0,\theta_1)$,然后重复应用上面两个方程,来接近$J(\theta_0,\theta_1)$的最小值,我们的预测函数就会越来越准确。
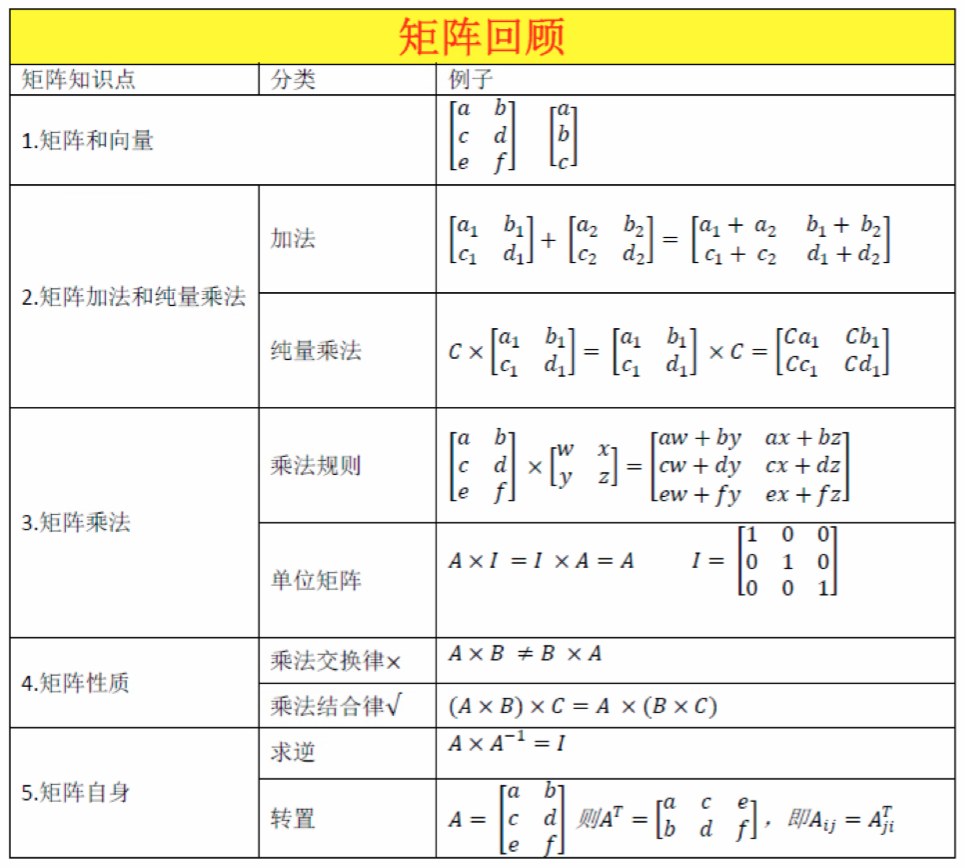
4 线性代数回顾
5 总结
本文首先介绍了什么是机器学习,以及机器学习的两个类别:
-
监督式学习(回归和分类);
-
非监督式学习。
其次对于监督式学习回归的最简单的例子,线性回归,我们定义了它的预测函数$h(\theta_0,\theta_1)$和成本函数$J(\theta_0,\theta_1)$。我们要做的是寻找最优的$\theta_0,\theta_1$找到全局最小值$J_{min}$,这可以结合梯度下降来实现,即我们只需要猜测一个预测函数的起始点$h(\theta_0,\theta_1)$,然后重复应用上面两个方程,来接近$J(\theta_0,\theta_1)$的最小值,我们的预测函数就会越来越准确。
repeat until convergence:
