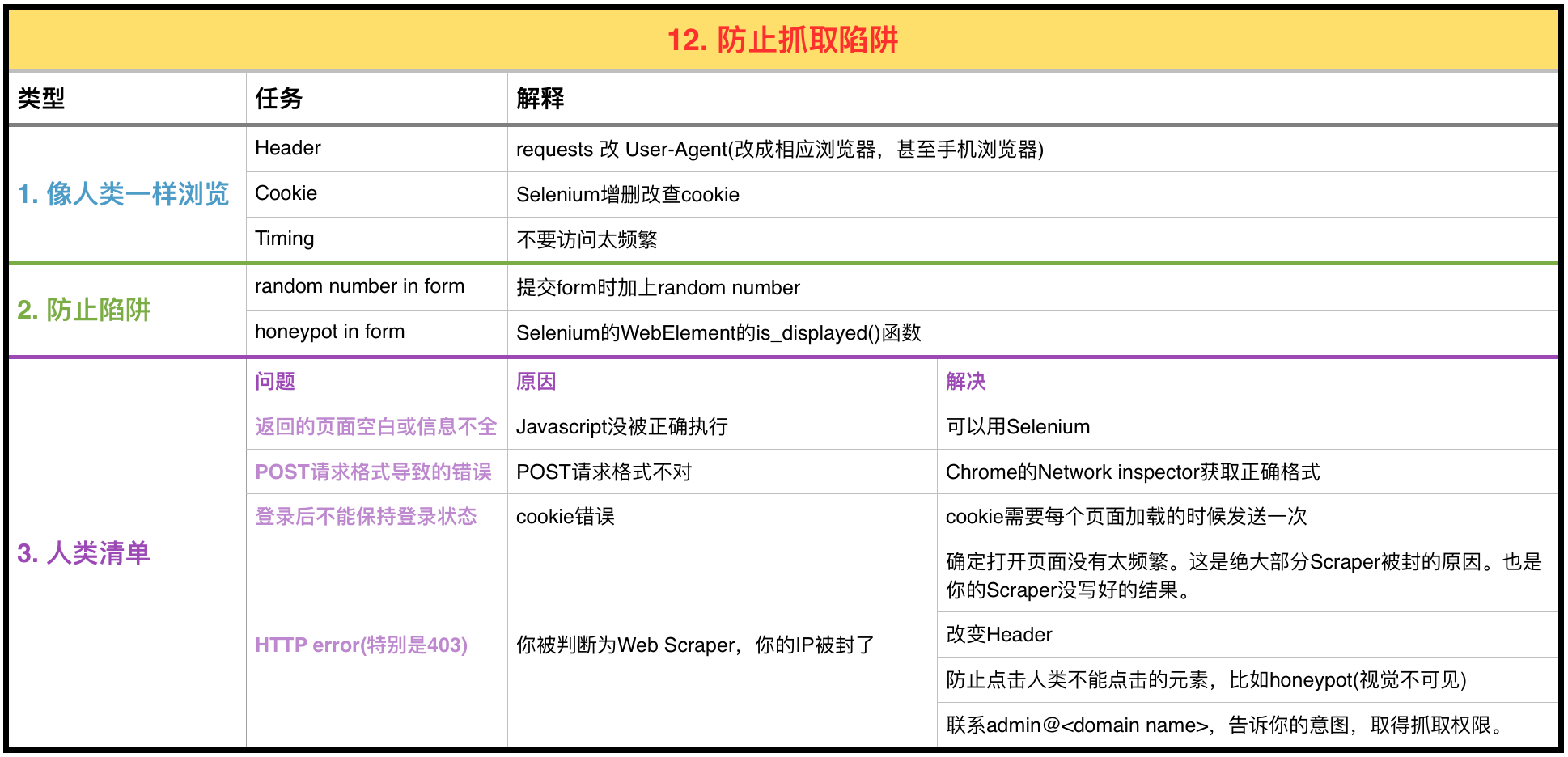
目录
本文重点介绍如何防止你的Web Scraper被网站侦查出来。
1 道德问题
为什么要教别人写出更好的Web Scraper是一个比较难回答的问题,有如下几个方面:
-
抓取那些不想被抓取的网站在某种程度上是道德容忍且法律允许的,比如让一些泄露其他网站客户信息的网站删除那些信息。Web Scraper可以收集这些信息然后让该网站删除。
-
可以帮助建立更好的反爬虫的网站。
-
隐藏任何有教育意义的信息都是不对的。
我只能说这么多了。
2 像人类一样浏览
防爬虫的关键在于如何区别Web Scraper和Human。虽然有些网站使用了较难处理CAPTCHA,但是还有很多很简单的处理可以让你的Web Scraper运行地更像人类。
2.1 调整Header
HTTP headers:are components of the header section of request and response messages in the Hypertext Transfer Protocol (HTTP). They define the operating parameters of an HTTP transaction.
requests在Advanced Scrapers (三):表单和登录中已经做过介绍。它不仅擅长表单提交,而且对于设置HTTP headers也非常方便。
HTTP定义了各种header类型,大部分都不常见。然而以下几个fields,却是被大部分浏览器广泛使用的。

而一个典型的python的HTTP header默认的User-Agent:Python-urllib/3.4,因此User-Agent的修改非常重要。
幸运的是,header可以用requests轻易修改,而https://www.whatismybrowser.com是一个服务端看到你的浏览器的属性的优秀网站。我们下面用requests来修改Web Scraper的header。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome",
"Accept":"text/html,application/xhtml+xml,application/xml; q=0.9,image/webp,*/*;q=0.8"}
url = "https://www.whatismybrowser.com/developers/what-http-headers-is-my-browser-sending"
req = session.get(url,headers=headers)
bsObj = BeautifulSoup(req.text,"html.parser")
print(bsObj.find("table",{"class":"table-striped"}).get_text)
# output
# <tr>
# <th>ACCEPT</th>
# <td>text/html,application/xhtml+xml,application/xml; q=0.9,image/webp,*/*;q=0.8</td>
# </tr>
# <tr>
# <th>ACCEPT_ENCODING</th>
# <td>gzip, deflate</td>
# </tr>
# <tr>
# <th>CONNECTION</th>
# <td>keep-alive</td>
# </tr>
# <tr>
# <th>HOST</th>
# <td>www.whatismybrowser.com</td>
# </tr>
# <tr>
# <th>USER_AGENT</th>
# <td>Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome</td>
# </tr>
# </table>>
可以清楚的看到,header已经被成功修改。而且有时候,手机版的网站显示的内容更干净更易抓取,比如可以将User-Agent改成User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53。
2.2 处理Cookies
处理cookies可以解决很多抓取的问题。但是cookie是一把双刃剑,网站可以通过你的cookie追踪你的进度,如果同一个cookie添加表单太频繁或者访问太多页面,服务器会切断你的表现异常的Scraper,从而使接下来的抓取失败。
-
Cookie在抓取网站上非常有用,有些网站需要你登录才能抓取;甚至有些网站不需要你每次登录都获取一个新的Cookie,一个旧的就可以用。
-
如果你只抓取某个特定网站,则我建议你研究下它的cookie。有许多工具可以显示cookie是如何设置的随着你浏览网页。EditThisCookie就是chrome下很有用的这类插件。
由于requests不会处理客户端的JavaScript,而当代cookie的大部分是客户端的JavaScript处理后产生的。因此可以用Selenium和PhantomJS来获取。
1
2
3
4
5
6
7
8
9
10
11
12
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomJS')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())
# output
# [{'name': '_gat', 'secure': False, 'path': '/', 'value': '1', 'expiry': 1469629021, 'domain': '.pythonscraping.com', 'httponly': False, 'expires': '周三, 27 7月 2016 14:17:01 GMT'}, {'name': '_ga', 'secure': False, 'path': '/', 'value': 'GA1.2.491484311.1469628421', 'expiry': 1532700421, 'domain': '.pythonscraping.com', 'httponly': False, 'expires': '周五, 27 7月 2018 14:07:01 GMT'}, {'name': 'has_js', 'secure': False, 'path': '/', 'value': '1', 'domain': 'pythonscraping.com', 'httponly': False}]
进一步,我们除了get_cookies(),还有delete_cookie(),delete_all_cookie(),add_cookie()。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomJS')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())
savedCookies = driver.get_cookies()
driver2 = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomJS')
driver2.get("http://pythonscraping.com")
driver2.delete_all_cookies()
for cookie in savedCookies:
driver2.add_cookie(cookie)
driver2.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver2.get_cookies())
现在driver2和driver1的cookie一样。
2.3 把握Timing
过于频繁地提交表单或者和网页互动会让你被注意到。你总是得保持单独网页的载入和数据请求到一个最小值。如果可能的话,可以在多个请求之间增加一个额外的time.sleep(3)。
3 常见的表单安全问题
在区别Web Scraping和人浏览网页的不同上,大部分网站的集中精力花在防止表单的提交和用户名注册和登录上。如果被恶意的大量虚假用户名注册,对网页的影响是巨大的。下面我们来看主要几个。
3.1 隐藏Input Field Value
hidden fields可以被浏览器看到,但是不能被人肉眼所见。
随着cookie用来存储数据并且在网站中传输,hidden fields逐渐失宠,直到它的另一个用途被发现:防止scraper提交表单。
下图是facebook登录页面的HTML,可以看到输入field只有用户名和密码,但是有很多hidden fields存在。
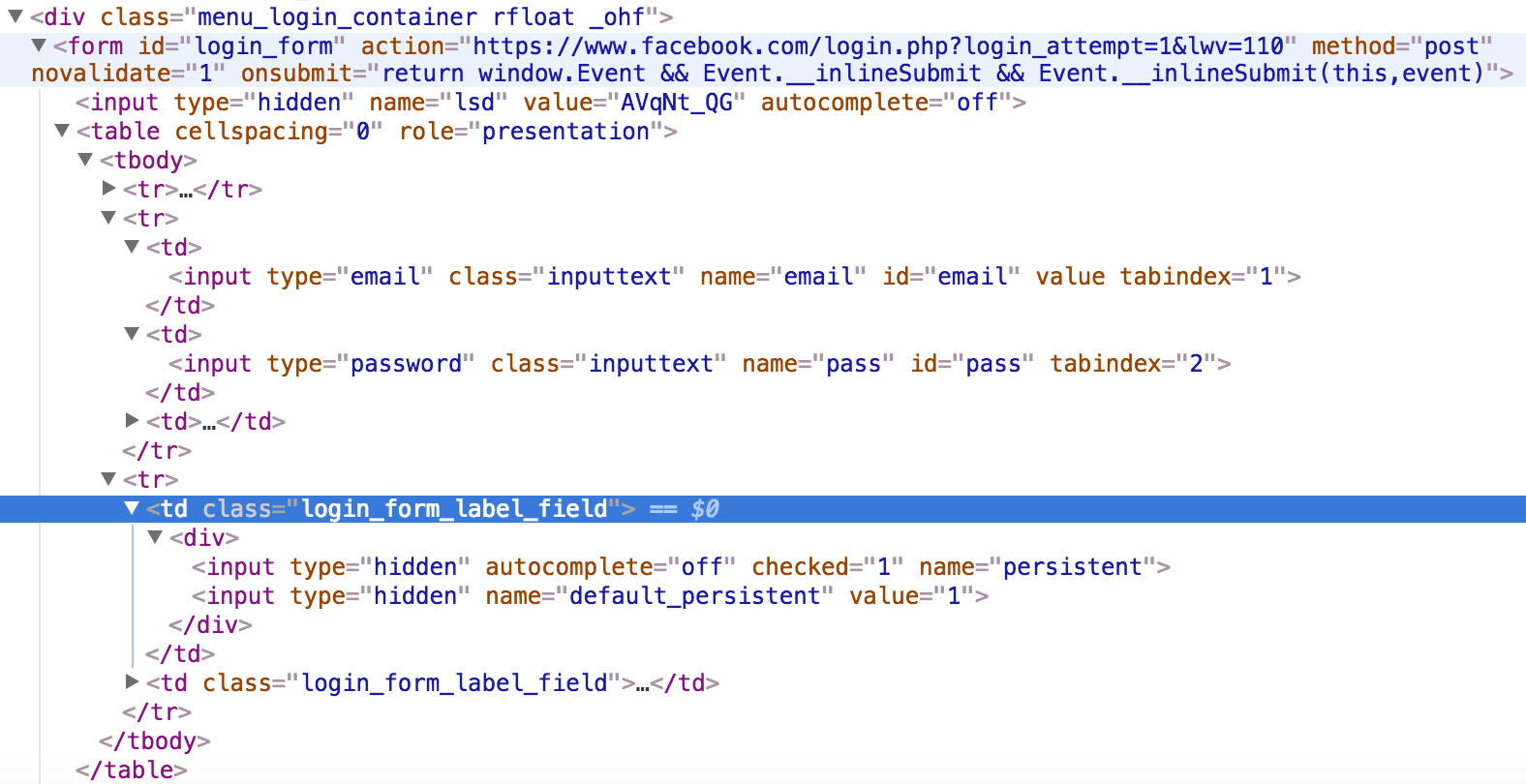
通常hidden fields用来防止Web Scraping有两种方式:
-
field可以被一个随机产生的数字绑定。如果precessor页提交表单的时候该数字不在,则服务器可以确定这次请求不是来自原始的网页,而是Web Scraper。解决方式是先scrape表单页,提取这个随机数,然后通过precessor页提交表单到服务器。
-
honeypot。即hidden fields却有一个类似
name=username或者email address的名字用来迷惑一般的Web Scraper。由于该标签用户看不见,如果你的Web Scraper提交类似的表单,则很容易就被识别。
3.2 防止Honeypot
对于上面提到的honeypot,该如何预防呢。
我们举一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<html>
<head>
<title>A bot-proof form</title>
</head>
<style>
body {
overflow-x:hidden; }
.customHidden {
position:absolute;
right:50000px;
}
</style>
<body>
<h2>A bot-proof form</h2>
<a href="http://pythonscraping.com/dontgohere" style="display:none;">Go here!</a>
<a href="http://pythonscraping.com">Click me!</a>
<form>
<input type="hidden" name="phone" value="valueShouldNotBeModified"/><p/>
<input type="text" name="email" class="customHidden" value="intentionallyBlank"/><p/>
<input type="text" name="firstName"/><p/>
<input type="text" name="lastName"/><p/>
<input type="submit" value="Submit"/><p/>
</form>
</body>
</html>
上面有个3个元素用三种不同的方式隐藏于用户:
-
第一个href用一个简单的CSS的display:none属性;
-
phone field 是一个hidden input field;
-
email field 向右移动了50,000 pixels。
那么如何解决呢。幸运的是Selenium可以渲染访问的页面,且可以区别是否视觉上出现在页面上的HTML元素,通过is_dispalyed()函数。
例如下面代码可以区别上例HTML中的隐藏元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
driver = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomJS')
driver.get("http://pythonscraping.com/pages/itsatrap.html")
links = driver.find_elements_by_tag_name("a")
for link in links:
if not link.is_displayed():
print("A trap link: %s" % link.get_attribute("href"))
inputs = driver.find_elements_by_tag_name("input")
for input in inputs:
if not input.is_displayed():
print("A trap input: %s" % input.get_attribute("name"))
# output
# A trap link: http://pythonscraping.com/dontgohere
# A trap input: phone
# A trap input: email
虽然你不想你的Web Scraper访问任何隐藏的field,但是你得确定你之前填写好的field的值可能会出现在某些hidden field里。你得确保这类hidden field要填写好。
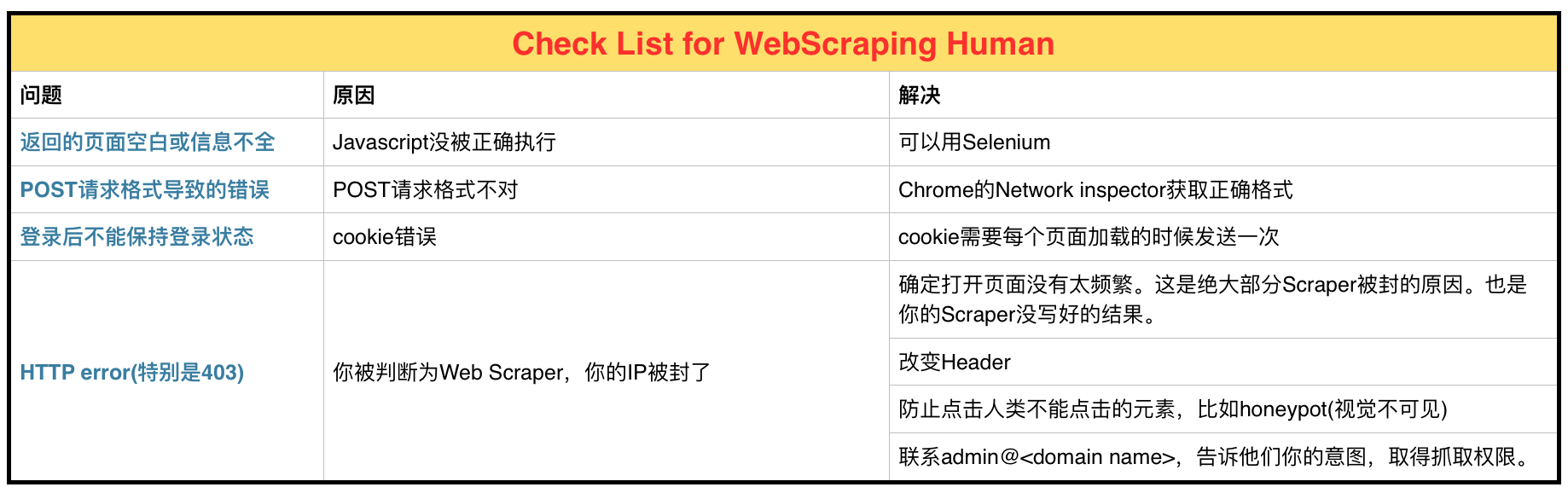
4 人类清单
下图总结了人类清单,供参考。
5 总结
本文介绍了如何像人类一样浏览:
-
用requests调整Header,特别是User-agent,要改成浏览器。
-
用Selenium增删改查Cookie,用以识别用户身份。
-
把握时机,不能太频繁的发送请求。
以及网站通常的防Web Scraper的方法之表单:
-
绑定随机数,在表单提交的时候;
-
设置隐藏Field,若填写则证明你是机器抓取(可以用Selenium的WebElement的is_displayed()函数来检查是否在网页上视觉可见)。
最后总结了一张人类清单,供Web Scraper出现问题时的参考。
本文总结成下面一张图。