
目录
- 1 介绍
- 2 Overview of Libaries
- 3 Processing Well-Formatted Text
- 4 Reading CAPTCHAs and Training Tesseract
- 5 Retrieving CAPTCHAs and Submitting Solutions
- 6 总结
- 6 参考资料
1 介绍
Machine Vision是计算机科学的热门领域,它的应用从google的自动驾驶技术到识别假币的自动贩卖机等无处不在。本文我们重点介绍其中的一小部分,text recognition即如何识别和使用基于图片的文本。
在网络上,文本在很多场景下被有意无意地转换成图片,比如:
-
验证码(CAPTCHAs),用以防止机器登录;
-
扫描的文件,可以节省输入文件文本的时间;
-
联系人里的邮箱地址,防止被爬虫抓取。
以上3种情况都使得Web Scraping变的困难。解决这些问题的关键在于如何将图片重新转换成文本,即OCR(Optical Character Recognition)。
OCR(Optical Character Recognition):the mechanical or electronic conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image (for example from a television broadcast)。
本文就ORC技术结合的Web Scraping做一个入门介绍。
2 Overview of Libaries
2.1 Pillow
Pillow是个小巧而强大的图像处理module。
安装Pillow module在terminal输入:pip3 install pillow即可。
Pillow module:adds image processing capabilities to your Python interpreter。
1
2
3
4
5
6
7
from PIL import Image, ImageFilter
kitten = Image.open("kitten.jpg")
#GaussianBlur is added to the orginal image
blurryKitten = kitten.filter(ImageFilter.GaussianBlur)
blurryKitten.save("kittent_blurred.jpg")
blurryKitten.show()
我们将会在后面用Pillow执行preprocessing on images使得机器更好识别图像化的文本。
2.2 Tesseract
Tesseract是个google支持的OCR module,被广泛认为是最好最精确的开源OCR系统。
Tesseract:optical character recognition engine for various operating systems。
安装Tesseract在terminal输入:brew install tesseract即可。
Tesseract有一个Python库pytesseract,安装只terminal输入:brew install pytesseract即可。
2.3 NumPy
虽然直接进行OCR并不需要NumPy,但是如果你需要训练Tesseract来识别额外的字符集或者字体,就需要用到NumPy。NumPy是一个处理线性代数和其他大规模数学应用的强大的库。Numpy可以用像素矩阵来处理图形,因此可以很好的结合Tesseract使用。
NumPy: a python module for large, multi-dimensional arrays and matrices, along with a large library of high-level mathematical functions to operate on these arrays。
安装NumPy module在terminal输入:pip3 install numpy即可。
关于具体使用,我们后面会详细介绍。
3 Processing Well-Formatted Text
3.1 OCR本地图片
3.1.1 Clean Image
我们现在使用pytesseract来OCR一个Well-Formatted的图片,如下。

1
2
3
4
5
6
7
8
9
10
11
from PIL import Image
import pytesseract
image = Image.open("text.png")
string = pytesseract.image_to_string(image)
print(string)
# output:
# This is some text, written in Arial, that will be read by
# Tesseract. Here are some symbols: !@#$%"&*()
我们看到除了^和*分别显示成"和*,其他都是正确的。
3.1.2 Slightly Dirty Image
现在我们将图片压缩后增加了背景渐变,使得OCR难度增加,请看下图。

1
2
3
4
5
6
7
#2 slightly dirty Well-Formateed Text
image = Image.open("text2.png")
string = pytesseract.image_to_string(image)
print(string)
# output
# This is some text, mitten in Anal, 1!" _,
# Tessetact. Here are some symbols: _
它的输出在背景深色的地方停止,并且增加了许多错误。
3.1.3 Fix Slightly Dirty Image
这种请看下Pillow就派上用场了,可以用一个阈值过滤器(threshold filter)来消除背景的渐变色,使得图片上的文本更clean。
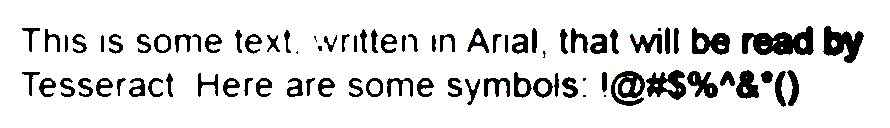
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from PIL import Image
import pytesseract
def cleanFile(filePath,newFilePath):
image = Image.open(filePath)
#Set a threshold value for the image, and save
image = image.point(lambda x:0 if x<143 else 255)
image.save(newFilePath)
return image
image = cleanFile('text2.png','text3_cleaned.png')
string = pytesseract.image_to_string(image)
print(string)
# output
# This IS some text‘ wntten In Anal, that will be readby
# Tesseract Here are some symbols: !@#$%"&'()
可以看到输出提高了很多,尽管某些标点符号有错误。
3.2 OCR网络图片
用Tesseract来读取本地图片上的文字似乎并不是那么有趣,我们来尝试读取下网络图片上的文字。
以Amazon的图书预览为例。虽然Amazon的robots.txt文件允许Web Scraper来读取网页上的产品信息,但是图书预览产生于用户触发的Ajax脚本,并且隐藏在多层divs下的图片中。
下面的代码浏览到托尔斯泰的《战争与和平》,打开图书预览,获取每一页的url,然后下载图面并进行OCR。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import time
from urllib.request import urlretrieve
import subprocess
from selenium import webdriver
#driver = webdriver.PhantomJS(executable_path='/Users/ryan/Documents/pythonscraping/code/headless/phantomjs-1.9.8-macosx/bin/phantomjs')
driver = webdriver.Chrome(executable_path="/Applications/chromedriver")
url = "https://www.amazon.com/War-Peace-Vintage-Classics-Tolstoy/dp/1400079985/ref=sr_1_1?ie=UTF8&qid=1469602093&sr=8-1&keywords=peace+and+war"
driver.get(url)
time.sleep(2)
driver.find_element_by_id("img-canvas").click()
#The easiest way to get exactly one of every page
imageList = set()
#Wait for the page to load
time.sleep(10)
print(driver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"))
while "pointer" in driver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"):
#While we can click on the right arrow, move through the pages
driver.find_element_by_id("sitbReaderRightPageTurner").click()
time.sleep(2)
#Get any new pages that have loaded (multiple pages can load at once)
pages = driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")
for page in pages:
image = page.get_attribute("src")
imageList.add(image)
driver.quit()
#Start processing the images we've collected URLs for with Tesseract
for image in sorted(imageList):
urlretrieve(image, "page.jpg")
p = subprocess.Popen(["tesseract", "page.jpg", "page"], stdout=subprocess.PIPE,stderr=subprocess.PIPE)
p.wait()
f = open("page.txt", "r")
print(f.read())
可以看到背景是白色的页面字体显示较清楚,而有色彩的会出错。
4 Reading CAPTCHAs and Training Tesseract
CAPTCHA即验证码对大多数人来说很熟悉,但是对于它的定义详细鲜有人知道。
CAPTCHA:Computer Automated Public Turing test to tell Computer and Humans Apart。
这个”笨重”的缩写,就像一个”笨重”的阻碍,架在网页和用户之间。不管用户是人类还是机器,都在为识别CAPTCHA而挣扎。
图灵测试(Turing Test):图灵1950年设计出这个测试,其内容是,如果电脑能在5分钟内回答由人类测试者提出的一系列问题,且其超过30%的回答让测试者误认为是人类所答,则电脑通过测试。
颇具讽刺的是我们本想用于测试机器而设置的图灵测试,却在测试人类自己上获得褒贬不一样的结果。众所周知的google reCAPTCHA将近25%的人类用户阻挡于网站之外。
大部分其他的CAPTCHA较简单。Drupal,一个流行的基于PHP的内容管理系统,有一个流行的CAPTCHA库,用于产生不同难度的CAPTCHA。一个典型的结果如下:
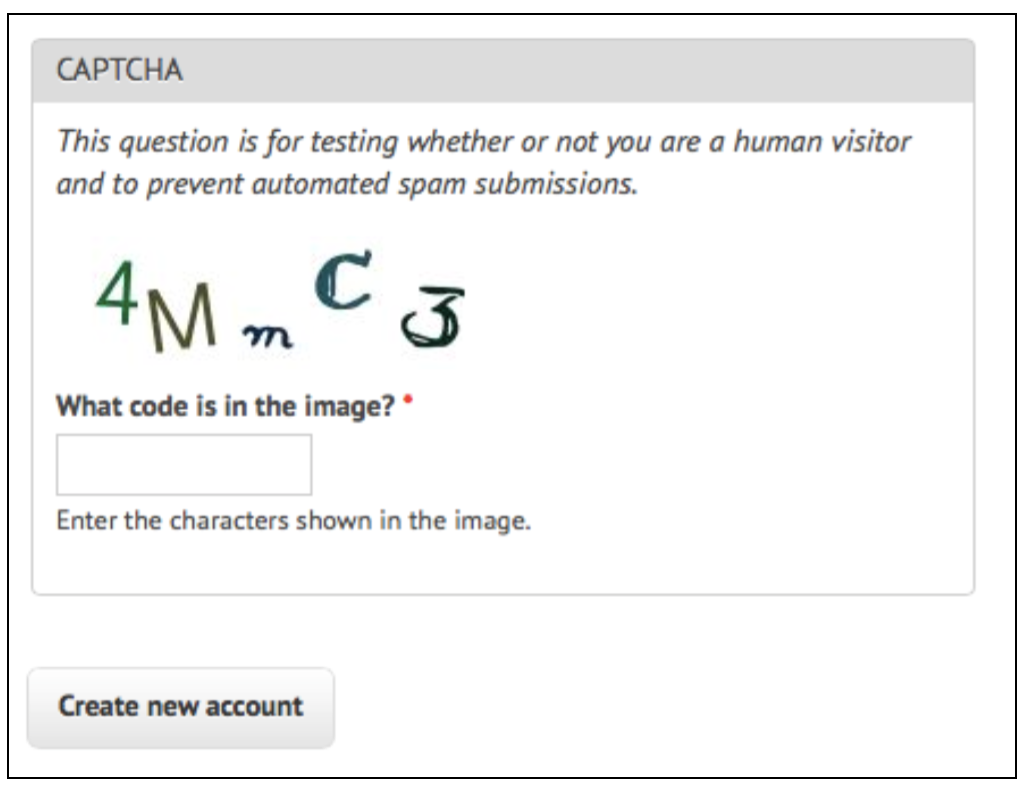
是什么让这个CAPTCHA对人类和机器阅读都如此容易呢?
-
字符没有重叠;
-
背景没有图片,线条和其它干扰图形;
-
字体比较固定;
-
背景和内容的对比度大。
但是这个CAPTCHA有一些弧线使得OCR有些挑战:
-
字母和数字同时使用,增加了OCR的可能字符个数;
-
字符的随机倾斜使人阅读起来没有障碍,却让机器阅读难度上了一个台阶;
-
手写字体的比较奇怪,使OCR更困难。例如”C”和”3”都有额外的线条,”m”显示过小,需要机器额外的训练才能解决。
当我们执行tesseract的时候,输出是空,识别不出来。
1
2
3
4
5
6
7
8
9
10
from PIL import Image
import pytesseract
image = Image.open("3.1_CAPTCHA.png")
image.show()
string = pytesseract.image_to_string(image)
print(string)
#output:
#
4.1 Training Tesseract
为了使得Tesseract能够识别字体,你需要提供每个字符的多个example。
这部分略。
5 Retrieving CAPTCHAs and Submitting Solutions
大部分基于图片的CAPTCHA有以下几个特点:
-
他们是动态产生的图片,由服务端的程序生成。该图片的src可能和正常的看起来不一样(例如src=”WebForm.aspx?id=8AP85CQKE9TJ”),但是可以用同样的方法下载和处理。
-
该图片的正确文本的答案存储在服务端的数据库里。
-
大部分CAPTCHA有等待时间。对于Wescraping来说这不是什么大问题。
获取CAPTCHA和上传答案分以下几步:
-
下载CAPTCHA图片到本地;
-
clean it,use tesseract to do OCR;
-
返回答案,用合适的表单参数。
作者在本书网站上写了一个CAPTCHA提交网页。我们用下面Web Scraping代码来破解它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
import subprocess
import requests
from PIL import Image
from PIL import ImageOps
def cleanImage(imagePath):
image = Image.open(imagePath)
image = image.point(lambda x: 0 if x<143 else 255)
borderImage = ImageOps.expand(image,border=20,fill='white')
borderImage.save(imagePath)
html = urlopen("http://www.pythonscraping.com/humans-only")
bsObj = BeautifulSoup(html.read(),"html.parser")
#Gather prepopulated form values
imageLocation = bsObj.find("img", {"title": "Image CAPTCHA"})["src"]
formBuildId = bsObj.find("input", {"name":"form_build_id"})["value"]
captchaSid = bsObj.find("input", {"name":"captcha_sid"})["value"]
captchaToken = bsObj.find("input", {"name":"captcha_token"})["value"]
captchaUrl = "http://pythonscraping.com"+imageLocation
urlretrieve(captchaUrl, "captcha.jpg")
cleanImage("captcha.jpg")
p = subprocess.Popen(["tesseract", "captcha.jpg", "captcha"], stdout=
subprocess.PIPE,stderr=subprocess.PIPE)
p.wait()
f = open("captcha.txt", "r")
#Clean any whitespace characters
captchaResponse = f.read().replace(" ", "").replace("\n", "")
print("Captcha solution attempt: "+captchaResponse)
if len(captchaResponse) == 5:
params = {"captcha_token":captchaToken, "captcha_sid":captchaSid,
"form_id":"comment_node_page_form", "form_build_id": formBuildId,
"captcha_response":captchaResponse, "name":"Ryan Mitchell",
"subject": "I come to seek the Grail",
"comment_body[und][0][value]":
"...and I am definitely not a bot"}
r = requests.post("http://www.pythonscraping.com/comment/reply/10",
data=params)
responseObj = BeautifulSoup(r.text)
if responseObj.find("div", {"class":"messages"}) is not None:
print(responseObj.find("div", {"class":"messages"}).get_text())
else:
print("There was a problem reading the CAPTCHA correctly!")
# output:
# Status message
# Your comment has been queued for review by site administrators and will be published after approval.
这个程序有50%由于字符数不是5而失败,有20%由于字符数是5但是答案不对而失败,剩下的30%是正确的(相当于每个字符的正确识别率为80%)。虽然30%看起来比较低,但是随机猜中的概率却是0.0000001%。只要运行3-4次就能提交一次正确答案比盲目的去猜1亿次是一个重大的提高。
6 总结
本文介绍了:
-
如何用Tesseract来进行OCR,对于背景颜色和字体颜色对比度不够的图片,需要用Pillow来进行图片预处理,增加对比度。
-
如何训练Tesseract来进行OCR。
-
如何在网站上读取CAPTCHA和提交答案。
最后加本文总结成下图以供参考。

