
目录
JavaScript是动态页面技术的基石(包括Ajax,DHTML),将HTML的数据展示层和数据更新层进行了解耦,使得我们在浏览动态网页的时候看到内容在更新HTML文件却没变。JavaScript使得我们之前用静态网页抓取的技术统统失效。解决的办法在于如何写出用Web Scraper解析JavaScript的程序。幸运的是,第三方库Selenium使得我们可以抓取一个真实运行在浏览器上的网页,让一切变的如此简单。本文我们主要来看看动态网页如何利用Selenium进行抓取。
客户端脚本语言是运行在浏览器而不是服务器的语言。因此客户端脚本的成功运行基于浏览器解析和执行该脚本的正确性。这就是为什么你可以如此轻松的在浏览器关闭JavaScript。
由于各个浏览器厂商的差异性,所以客户端脚本语言的数量比服务端脚本语言的数量少很多。对于Web Scraping来说,这是好事,更少种类的语言意味着更好处理。
在把部分情况下,你主要会遇到两种客户端脚本语言,ActionScript和JavaScript。其中 ActionScript(Flash application),常被用于stream multimedia files作为online game的平台。现在ActionScript的使用相比于十年前已经大大减少。
由于需要Web Scrape ActionScript的场景比较少,本文重点关注Web Scrape JavaScript
JavaScript,是当今最为广泛应用的客户端脚本语言,可用于手机用户信息,不重载来提交表单,内嵌多媒体甚至是驱动整个oneline game。
即使最简单的网页也可能包括Javascript,它常常嵌在<script>标签里,如:
1
2
3
<script>
alert("This creates a pop-up using JavaScript");
</script>
1 A Brief Introduction to JavaScript
JavaScript是一门弱类型语言(weakly typed language)
下面是一个JavaScript的对Fibonacci数列的实现,里面包括了函数声明,变量声明,匿名函数,函数调用等实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<script>
var fibonacci = function() {
vara=1; varb=1;
return function () {
var temp = b;
b=a+b;
a = temp;
return b;
}
}
var fibInstance = fibonacci();
console.log(fibInstance()+" is in the Fibonacci sequence");
console.log(fibInstance()+" is in the Fibonacci sequence");
console.log(fibInstance()+" is in the Fibonacci sequence");
</script>
常见的JavaScript库有以下几种,供读者参考。
jQuery: a cross-platform JavaScript library designed to simplify the client-side scripting of HTML。
Google Analytics: freemium web analytics service offered by Google that tracks and reports website traffic。
Google Map:a web mapping service developed by Google。
用Python来执行包括这些JavaScript Libararies的代码非常消耗时间和CPU。
2 Selenium
到目前为止,我们与服务器发收数据的唯一方式是通过HTTP请求来获得响应。如果你遇到一个网页在更新数据却没有重载页面(reload page),那这个网页很大可能在用Ajax或者HTML。
Ajax:short for asynchronous JavaScript and XML),is a set of web development techniques using many web technologies on the client-side to create asynchronous Web applications by decoupling the data interchange layer from the presentation layer,which means updating diplay content without reload the entire page。
DHTML:an umbrella term for a collection of technologies used together to create interactive and animated web sites by using a combination of a static markup language (such as HTML),a client-side scripting language (such as JavaScript),a presentation definition language (such as CSS), and the Document Object Model。
如果你scrape一个网站发现它的显示和source code不一样;或者网页有一个重载页面将你redirect到另一个页面,但是你的网址却没有变。
任何上述两种情况都是由于你的Web Scraper程序不能成功执行相应的JavaScript。解决这两种情况只有两种方法:
-
直接scrape JavaScript;
-
使用能执行JavaScript的Python module然后从网页中scrape就像你正常浏览一个网站一样。
关于用Selenium 执行 JavaScript进行Web Scrape请见这里。
3 Handling Redirects
URL Redicret:分为两种情况。
1.服务器端的Redirects,会在页面加载前自动更改url,因此可以简单地用Python的urllib执行(自动处理)。需要注意的是,最后地址栏返回的url可能不是你刚开始输入的url。
2.客户端的Redirects是在客户的浏览器上执行的Javascript,因此我们也可以用Selenium抓取。问题的关键在于如何告诉SeleniumJavaScript执行的结束。
下列代码用一种巧妙的办法将Redicect的结束和原HTML的tag的消失绑定在一起。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from selenium import webdriver
import time
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print("Timing out after 10 seconds and returning")
return
time.sleep(1)
try:
elem == driver.find_element_by_tag_name("html")
except StaleElementReferenceException:
print("original page disappear")
return
driver = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomjs')
driver.get("http://pythonscraping.com/pages/javascript/redirectDemo1.html")
waitForLoad(driver)
print(driver.page_source)
4 总结
本文着重介绍了如何用Python scrape JavaScript。由于Python自己对JavaScript执行的低效,我们可以借助第三方库Selenium来抓取页面,同时也可以用它来处理客户端的Redirects。
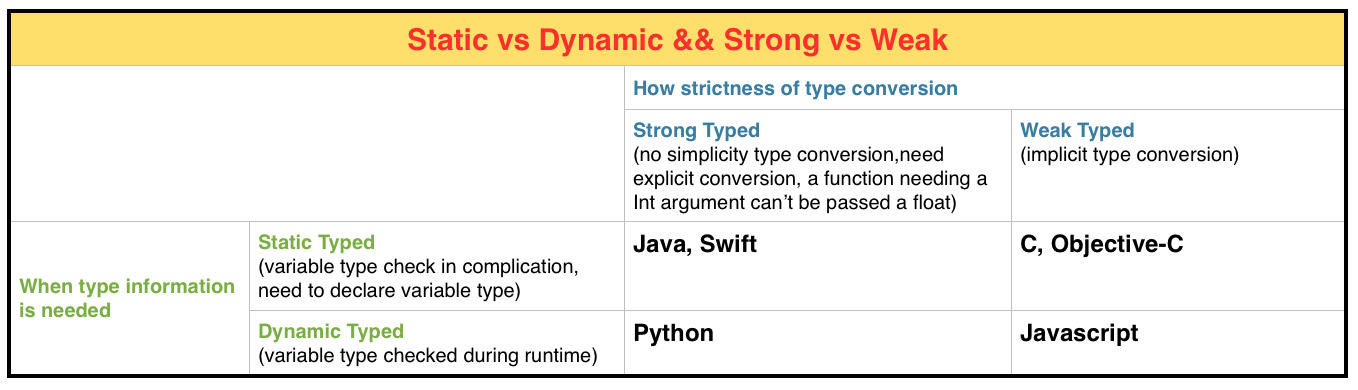
最后,本文总结成下图以供参考。

