目录
- 1 Python Requests Library
- 2 Submitting a Form
- 3 Handling Logins and Cookies
- 4 Other Form Problems
- 5 总结
- 6 参考资料
现在的网页正朝着社交媒体,用户交互方向快速发展。由此而来两个实际问题:
-
如何提交表单(基本表单,其他input,以及文件图像上传);
-
如何登陆网页;
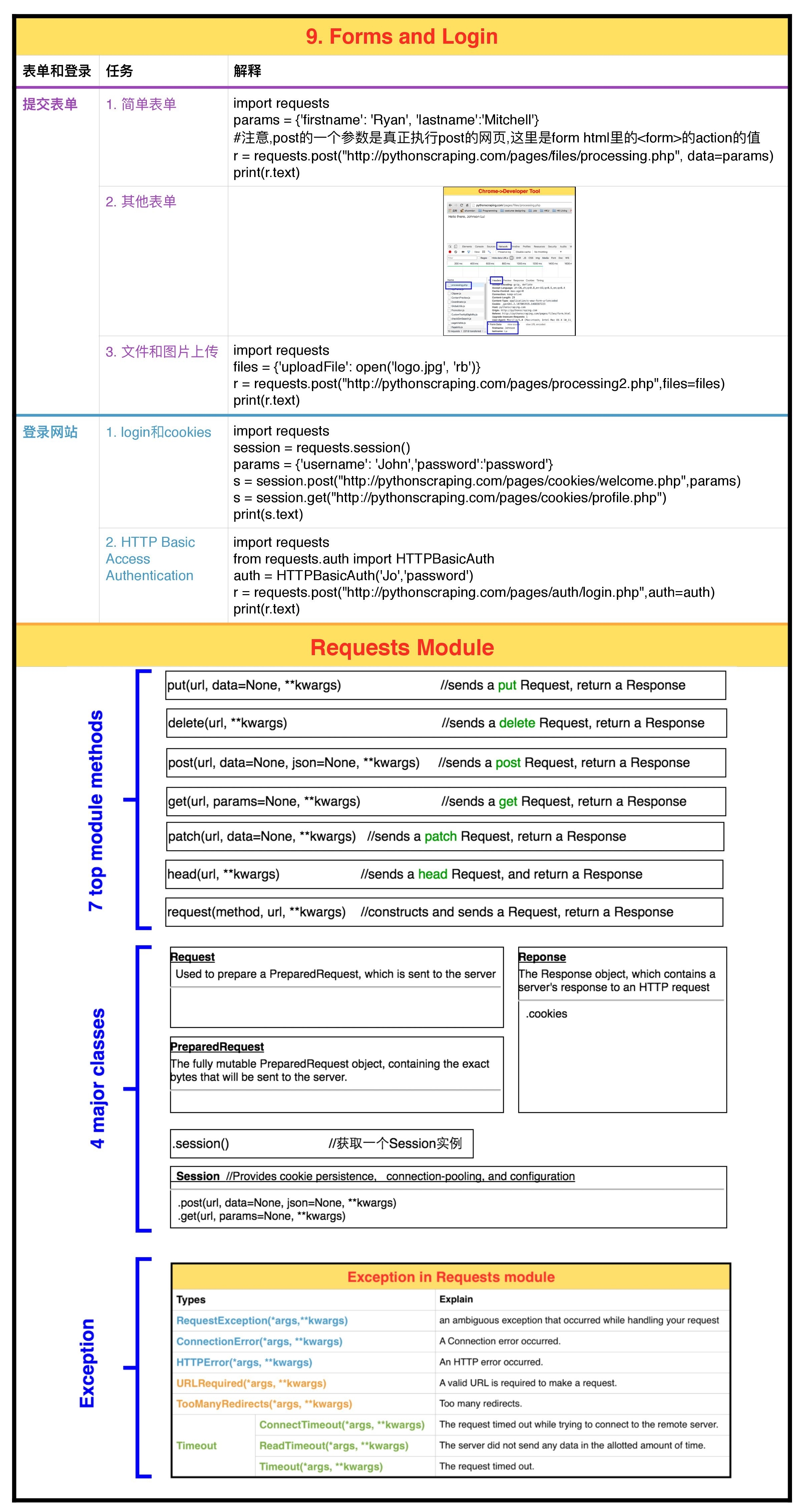
1 Python Requests Library
表单的提交是通过HTTP的POST访问方式来进行的。类似与网页的link tag帮我们格式好GET请求,HTML的表单帮我们格式好POST请求。
对于POST等除了GET的HTTP访问方式,urllib可能没有那么方便,稍显复杂。这个时候第三方库Requests就派上大用场了。
Requests:an elegant and simple HTTP library for Python, built for human beings。
Requests的安装和其他第三方库一样,在terminal输入: pip3 install requests。Requests的库主要由以下3个方面构成:7个主方法(包括常用的增删改查),4个主类(Request,PreparedRequest,Response和Session)以及Exception。如下图。

2 Submitting a Form
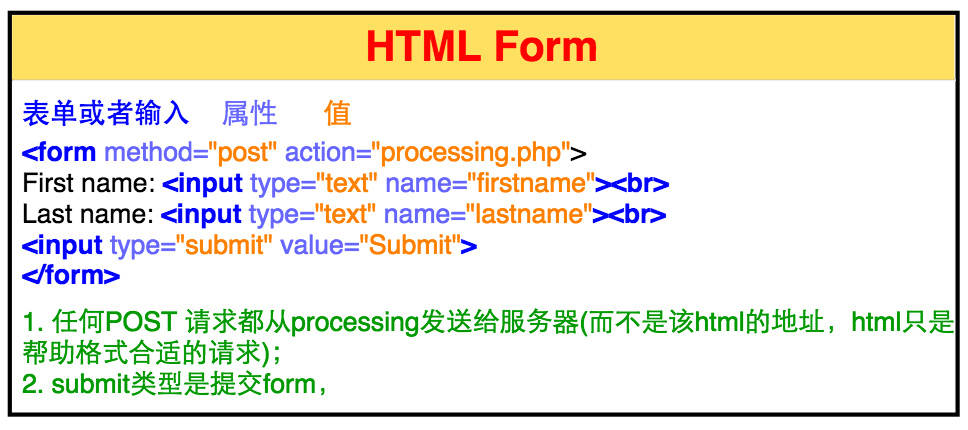
一个表单的基本格式如下图(我们用本书的网站做了一个简单的表单):
-
由
<form>将多个<input>包括在一起。 -
<form>的method是HTTP4种主要访问方式之一,这里是"post";action是提交这个request的页面,这里是"processing.php"而不是该html所在的页面(这个非常重要,当你点击submit,该html会将post的信息格式好发给"processing.php",由它来真正发出post请求向服务器)。 -
<input>的type可以是text,radio,checkbox,option,file,image等;但最后一个<input>的type必须是submit用来提交表单。
2.1 Basic Form
我们来看看如何用requests执行一个简单的表单提交请求。
1
2
3
4
5
6
7
8
9
import requests
params = {'firstname': 'Ryan', 'lastname':'Mitchell'}
#注意,post的第一个参数是真正执行post的网页,这里是form html里的<form>的action的值
r = requests.post("http://pythonscraping.com/pages/files/processing.php", data=params)
print(r.text)
#Output:
# Hello there, Ryan Mitchell!
是不是很简单呢,需要注意的是post的第一个参数是真正执行post的网页,这里是form的action的值对应的绝对URL而不是form所在的html。
2.2 Radio Buttons, Checkboxes, and Other Inputs
就像上面提到的,并不是所有表单都只由type=’‘text’‘的input组成,还有radio,checkbox,option,file,image,或者其他html5和javascript的类型。但是不管涉及的是什么类型,我们只需要注意该类型的变量名和值:
-
变量名在
name属性里; -
值在
value属性里,或者在你点击submit之后由javascript填满。
如果你对value的值不是很确定,可以用下面这个方法:
对于GET,通常只需要看它的URL,比如http://domainname.com?thing1=foo&thing2=bar对应的params = {'thing1': 'foo', 'thing2':'bar'}。对于某些更复杂的POST,可以见下图。

用chrome的开发者工具->Network->action page->header->data。可以清楚地看到{'firstname': 'Johnson', 'lastname':'Lu'}。
2.3 Files and Images
虽然file uploads在互联网上很常见,但是web scraping里用到file uploads并不多见。如果你想写一个包含file uploads的测试程序,则下面内容还是很有用的。我们用本书的另一个文件上传网页做例子,它的HTML如下:

可以看到和一个基本的form没有本质差别,除了type='file'。file uploads的Requests的代码如下。
1
2
3
4
5
6
7
8
import requests
files = {'uploadFile': open('logo.jpg', 'rb')}
r = requests.post("http://pythonscraping.com/pages/processing2.php",files=files)
print(r.text)
#Output:
# The file logo.jpg has been uploaded. <a href="/pages/uploads/logo.jpg">Link</a>
是不是很简单呢?
3 Handling Logins and Cookies
目前为止,我们接触的是POST表单,这和login用户名让我们长期处在登录状态中的操作有什么不同呢?
现代网页用cookies来追踪登录的用户。一旦你在某个网站登录了你的用户名,则该网站会在你的浏览器里存储一个cookie。该cookie通常包含了服务器产生的令牌(token),timeout以及追踪信息。在你登录之后,登出之前访问该网站的每一个网页,这个cookie都会被作为你的授权证据展示给网页。
小型文本文件(cookie):网站为了辨别用户身份而储存在浏览器上的数据(通常经过加密)。
虽然对于网页开发者,coolie用来辨别用户身份给很好用;但是对于web scrapers,cookie有时候会出问题。你可以提交一个login表单,但是提交后如果你没有存储返回的cookie,下一个你访问的网页就好像你没有在登录状态下访问的网页。
请看下面login form的例子,
- 它存在于
http://pythonscraping.com/pages/cookies/login.html; - 表单提交自
http://pythonscraping.com/pages/cookies/welcome.php; - 登录后页面是
http://pythonscraping.com/pages/cookies/profile.php
访问http://pythonscraping.com/pages/cookies/profile.php会先检查浏览器里有没有在login.html登录后产生的cookie,没有则会有一个错误信息并且建议你先登录。
追踪cookie用Requests Module非常简单。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import requests
params = {'username': 'Johnson','password':'password'}
r = requests.post("http://pythonscraping.com/pages/cookies/welcome.php",params)
print("Cookie is set to:")
print(r.cookies.get_dict())
print('-------------')
print("Going to profile page...")
r = requests.get("http://pythonscraping.com/pages/cookies/profile.php", cookies=r.cookies)
print(r.text)
#Output:
# Cookie is set to:
# {'loggedin': '1', 'username': 'Johnson'}
# -------------
# Going to profile page...
# Hey Johnson! Looks like you're still logged into the site!
这里我们首先将登录参数POST给welcome.php,然后从响应实例中获取cookies,最后用该cookies一GET方式访问profile.php。
这个代码在简单的情况下工作良好,但是如果是一个经常修改cookies的网站呢(哪种实际情况)?或者你就不想触碰cookie,有什么更好的办法吗?Request Module提供了一个Session类,完美地工作在这些情况下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import requests
session = requests.session()
params = {'username': 'John','password':'password'}
s = session.post("http://pythonscraping.com/pages/cookies/welcome.php",params)
print("Cookie is set to:")
print(s.cookies.get_dict())
print('-------------')
print("Going to profile page...")
s = session.get("http://pythonscraping.com/pages/cookies/profile.php")
print(s.text)
#Output:
# Cookie is set to:
# {'loggedin': '1', 'username': 'John'}
# -------------
# Going to profile page...
# Hey John! Looks like you're still logged into the site!
在这个例子里,Session实例管理了所有的session的信息,比如cookies,headers,甚至其他建立在HTTP上面的协议比如HTTTPAdapters。
3.1 HTTP Basic Access Authentication
在cookies发明之前,我们处理login的最普遍的方法之一是用 HTTP basic access authentication。现在你还能看到这样的网站,特别是在高安全级别和大公司的网站。
我们用下面这个HTTP Basic Access Authentication 网站来写一个简单代码。
1
2
3
4
5
6
7
8
9
import requests
from requests.auth import HTTPBasicAuth
auth = HTTPBasicAuth('Jo','password')
r = requests.post("http://pythonscraping.com/pages/auth/login.php",auth=auth)
print(r.text)
#Output:
# <p>Hello Jo.</p><p>You entered password as your password.</p>
4 Other Form Problems
网站的表单提交是Web Scraper一个重要目标,因此很多网站建立了表单反爬虫机制,关于这些细节,我们将在第12篇笔记中介绍。
5 总结
最后将本文总结成下图以供参考。