目录
1 介绍
在之前的笔记中,我们处理的data大部分是数字或者简单的字符串。且在大部分情况下,we simple store the data without further conducting analysis after the fact。本文我们就来尝试分析英文文本,从统计概率和词性分析两类角度入手。
2 自然语言处理实例
2.1 Generating Summary from Content
在前一篇笔记中,我们将文本分成n-grams,并且将其频数作为键值一起存储在有序字典(OrderedDict)里。换言之,它可以回答哪种短语(n-grams)是最常用的这一问题。
那么如何利用这一n-gram的数据呢?这类数据可以根据最受欢迎的短语来生成用来生成自然发音的数据库(natural-sounding data summary);也可以作为生产文章总结的出发点。
作为后者的例子,我们以美国第九任总统威廉·亨利·哈里森的一篇演讲稿作为原始数据,稍微修改下前一篇笔记n-grams的代码,看看如何生成文章总结。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
...
txtFile = urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt")
content = str(txtFile.read(), 'utf-8')
ngrams = ngrams(content,2)
sortedNGrams = OrderedDict(sorted(ngrams.items(), key=lambda item: item[1], reverse=True))
for k,v in sortedNGrams.items():
print(k,v)
#Output
# of the 212
# in the 62
# to the 60
# by the 41
# the Constitution 32
# of our 29
# to be 26
# ...
可以看到在这些高频词里,真正有用的比如是the Constituion;而例如of the,in the等都是没有实际意义的词。我们能否进一步准确地剔除这些无实际意义的词呢。
幸运的是,已经有前人帮我们整理这些interesting words和uninteresting words的区别。Brigham Young University的语言学教授Mark Davies维护着(当代美式英语大全Corpus of Contemporary American English),其中包括了450 million words。
里面的前5,000个高频单词列表是免费的,实际上,我们只需要前100个就能将我们之前的输出结果大大改善了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
...
def isCommon(ngram):
commonWords = ["the", "be", "and", "of", "a", "in", "to", "have", "it",
"i", "that", "for", "you", "he", "with", "on", "do", "say", "this",
"they", "is", "an", "at", "but","we", "his", "from", "that", "not",
"by", "she", "or", "as", "what", "go", "their","can", "who", "get",
"if", "would", "her", "all", "my", "make", "about", "know", "will",
"as", "up", "one", "time", "has", "been", "there", "year", "so",
"think", "when", "which", "them", "some", "me", "people", "take", "out", "into", "just", "see", "him", "your", "come", "could", "now",
"than", "like", "other", "how", "then", "its", "our", "two", "more",
"these", "want", "way", "look", "first", "also", "new", "because",
"day", "more", "use", "no", "man", "find", "here", "thing", "give",
"many", "well"]
for word in ngram:
if word in commonWords:
return True
return False
...
#Output
# united states 10
# general government 4
# executive department 4
# government should 3
# same causes 3
# chief magistrate 3
# mr jefferson 3
# called upon 3
可以看到最高频的是united states和executive department,是我们期待的总统演讲应该包括的高频词,good。
现在,一些高频词已经被我们提取出来了,如何利用这些高频词作为keyword来生成这篇演讲稿的summary呢。其中一个方法便是搜索每一个“popular” n-gram在文本中第一次出现的句子。应用这个方法到上述5个高频词,我们获得如下5个sentence:
-
The Constitution of the United States is the instrument containing this grant of power to the several departments composing the government.
-
Such a one was afforded by the executive department constituted by the Constitu‐ tion.
-
The general government has seized upon none of the reserved rights of the states.
-
Called from a retirement which I had supposed was to continue for the residue of my life to fill the chief executive office of this great and free nation, I appear before you, fellow-citizens, to take the oaths which the constitution prescribes as a neces‐ sary qualification for the performance of its duties; and in obedience to a custom coeval with our government and what I believe to be your expectations I proceed to present to you a summary of the principles which will govern me in the dis‐ charge of the duties which I shall be called upon to perform.
-
The presses in the necessary employment of the government should never be used to clear the guilty or to varnish crime.
虽然这不能作为最终的summary,但是这5句基本上将原来的217句中的主要内容提炼出来了。如果要正式发布,我们还需要进一步工作,但是我们到目前为止的工作的确迈出了不错的第一步。
2.2 Markov Models
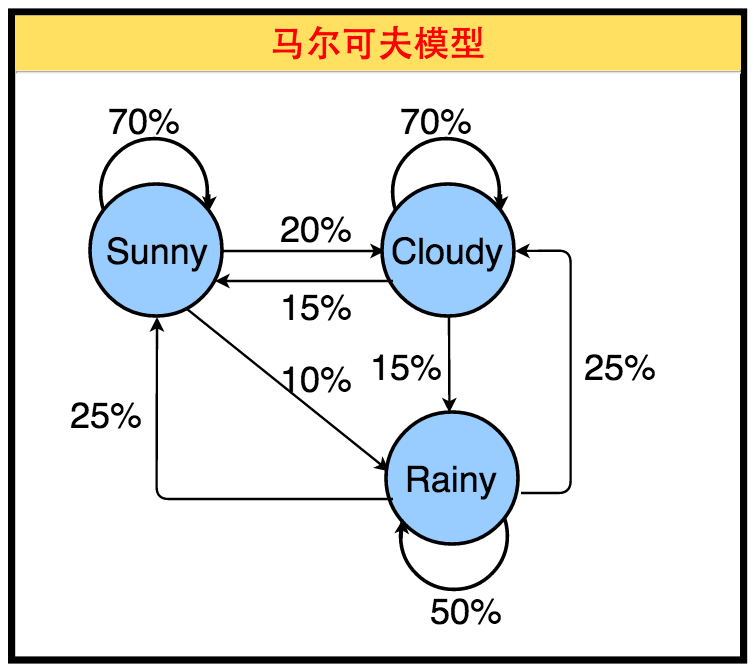
马尔可夫模型(Markov Models):一个根据当前状态预测下个状态(下个状态们的概率分布已知)的统计模型。广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。
下图展示了一个基本的基于马尔科夫模型的天气系统。每一个天气(Sunny,Cloudy,Rainy)的下一个状态可以是自己或者其他两个状态。下个状态们的概率总和为100%。因此对下一状态的预测就取决于两个参数,即当前状态和下一状态们的概率分布。比如Rainy有25%概率是Sunny。
那么如何利用马尔可夫模型和总统演讲稿的内容自动生成有原始文章气质的100个单词的句子呢。请看下面代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
from urllib.request import urlopen
from random import randint
import re
#get the total occurence of a word
def subsequentialWordsTotalOccurence(subsequentialWordsDictionary):
sum = 0
for word, occurence in subsequentialWordsDictionary.items():
sum += occurence
return sum
#get the random next word of the word
def retrieveSubsequentialWordRandomly(subsequentialWordsDictionary):
randomIndex = randint(1,subsequentialWordsTotalOccurence(subsequentialWordsDictionary))
for word, occurence in subsequentialWordsDictionary.items():
randomIndex -=occurence
if (randomIndex <=0):
return word
#build a dictionary of dictionary, as the input of Markov Models
def buildWordsDict(text):
punctuation = [',',':','.','?','!']
for symbol in punctuation:
text = text.replace(symbol," "+symbol+" ")
text = re.sub("\n+"," ",text)
text = re.sub(" +"," ",text)
# text = text.lower()
words = text.split(" ")
words = [word for word in words if word != ""]
mainWordDict = dict()
for i in range(len(words)-1):
word = words[i]
subsequentialWord = words[i+1]
if word not in mainWordDict:
mainWordDict[word] = dict()
subsequentialWordsDict = mainWordDict[word]
if subsequentialWord not in subsequentialWordsDict:
subsequentialWordsDict[subsequentialWord] = 1
else:
subsequentialWordsDict[subsequentialWord] +=1
return mainWordDict
#get words dictionary
textFile = urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt")
content = str(textFile.read(), 'utf-8')
wordDict = buildWordsDict(content)
wordsLength = 100
makeupSentence = ""
startWord = "I"
for i in range(wordsLength):
makeupSentence += startWord + " "
startWord = retrieveSubsequentialWordRandomly(wordDict[startWord])
print(makeupSentence)
# Output
# I sincerely believe to make all that they respectively claim or rather of that of the lapse of their own independence and maintain their country . Some of the great a motive for all that instrument could have acted in war , as is in the way of ultimate decision there was observable as the world may be content with our Constitution to justify me , it is not to control the best historians agree in legislation could then been the Constitution from the tendency of them his assent . Without denying that can unmake , nothing upon the want
我们来分析下代码:
-
buildWordsDict(text):speech文本清理后(替换换行,多个空格为1个空格,对待标点也和一个独立word一样)用空格分成word的list。然后建立一个2维dictionary,第一层key是当前word,value是一个dictionary;该dictionary的key是当前word后面的那个word,value是频数。这样我们就建立了一个Markov Models的原始模型。 -
再根据两个辅助函数
subsequentialWordsTotalOccurence(subsequentialWordsDictionary)和retrieveSubsequentialWordRandomly(subsequentialWordsDictionary)将频数转成频率后随机访问下一个word。
我们最后生成了100个单词以’I’开头的基于该演讲稿句子,读取来还是感觉略通顺的。
2.3 Six Degree Wikipedia Conclusion
之前我们在第3篇笔记:BeautifulSoup实战中介绍过六度维基理论并且在第5篇笔记:数据存储中将数据存成两张Table,即pages(ID,URL)和links(ID,fromPageID,toPageID)。但是对于如何从Kevin Bacon找到目标,我们还没有去解决。本部分我们将用有向图(Directed Graph)的宽度搜索(Breadth-First Search)算法来完成这个六度维基理论这个project。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pymysql
connection = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',
user='root', passwd='640401', db='mysql', charset='utf8')
cursor = connection.cursor()
cursor.execute("USE wikipedia")
class SolutionFound(RuntimeError):
def __init__(self,message):
self.message = message
def getLinks(fromgPageID):
cursor.execute("SELECT toPageID from links where fromPageID = %s",(fromgPageID))
if cursor.rowcount == 0:
return None
else:
# the results row only contains toPageID, thus the first item is selected
return [x[0] for x in cursor.fetchall()]
def constructDict(curentPageID):
links = getLinks(curentPageID)
if links:
# zip key list and value list(item is dictionary) into a dictionary
return dict(zip(links,[{}]*len(links)))
return {}
#The link tree may either be empty or contain multiple links
def searchDepth(targetPageID, currentPageID, linkTree, depth):
if depth == 0:
#Stop recursing and return, regardless
return linkTree
if not linkTree:
linkTree = constructDict(currentPageID)
if not linkTree:
#No links found. Cannot continue at this code
return {}
if targetPageID in linkTree.keys():
print("TARGET " + str(targetPageID) + " Found!")
raise SolutionFound("Page: " + str(currentPageID))
for branchKey, branchValue in linkTree.items():
try:
#Recurse here to continue building the tree
linkTree[branchKey] = searchDepth(targetPageID,branchKey,branchValue,depth-1)
except SolutionFound as e:
print(e.message)
raise SolutionFound("PAGE: " + str(currentPageID))
return linkTree
try:
searchDepth(18885,1,{},4)
print("No Solution FOund")
except SolutionFound as e:
print(e.message)
#Output
# TARGET 18885 Found! //Terry_Jones
# Page: 18830 //Douglas_Adams
# PAGE: 3 //San_Diego_Comic-Con_International
# PAGE: 1 //Kevin Bacon
# 即Kevin Bacon -> San_Diego_Comic-Con_International -> Douglas Adams -> Terry Jones
代码分析如下:
-
getLinks(fromgPageID)和constructDict(curentPageID)是连个辅助函数; -
searchDepth(targetPageID, currentPageID, linkTree, depth)用宽度搜索来寻找目标ID,即先遍历第一层,如果没找到,则遍历第二层,迭代直到找到为止。
最后我们找从Kevin Bacon到Terry Jones的link,返回Kevin Bacon -> San_Diego_Comic-Con_International -> Douglas Adams -> Terry Jones,如果去wiki上check一下,可以确定是对的。
3 Natural Language Toolkit
到目前为止,我们都是集中在利用统计学来寻找最受欢迎的单词或者短语,但是对理解单词本身的含义却没有触及。这部分我们就来看看如何利用NLTK(Natural Language Toolkit)来理解单词意思。
NLTK:the Natural Language Toolkit, a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
3.1 安装
两步安装。
-
安装nltk module。terminal输入:
pip3 install nltk -
安装完nltk module相关module。terminal 输入
python3 #进入python3import nltk nltk.download()。
3.2 NLTK概率分析
下面我们从text object,frequency distribution,ngrams以及iteration来略略感受下nltk的强大。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
from nltk import word_tokenize,FreqDist,bigrams,ngrams
from nltk import Text
from nltk.book import text6 #直接可用book下的attribute,如果用improt nltk,book,你得book.attribute
#1. text object
tokens = word_tokenize("Here is some not very interesting text")
text = Text(tokens)
print(len(text6)/len(text))
# Output
# 2423.8
#2. freuqncy distribution
fdist = FreqDist(text6)
print(fdist.most_common(10))
print(fdist["Grail"])
# Output
# [(':', 1197), ('.', 816), ('!', 801), (',', 731), ("'", 421), ('[', 319), (']', 312), ('the', 299), ('I', 255), ('ARTHUR', 225)]
# 34
#3. n-grams
bigrams = bigrams(text6)
bigramsDist =FreqDist(bigrams)
print(bigramsDist[("Sir","Robin")])
# Output
# 18
fourgrams = ngrams(text6,4)
fourgamsDist =FreqDist(fourgrams)
print(fourgamsDist[("father","smelt","of","elderberries")])
# Output
# 1
#4. iteration for text object, frequency distribution, ngrams
fourgrams = ngrams(text6,4)
for fourgram in fourgrams:
if fourgram[0] == "father":
print(fourgram)
# Output
# ('father', 'smelt', 'of', 'elderberries')
# ('father', 'owns', 'the', 'biggest')
# ('father', ',', 'who', 'wishes')
# ('father', ',', 'that', "'")
# ('father', '--', 'GUEST', '#')
# ('father', '--', 'GUEST', '#')
# ('father', ',', 'who', ',')
3.3 NLTK词典学分析
homonyms:two words are considered homonyms if they were spelling and pronounced in the same way。
He was objective in achieving his objective of writing an objective philosophy, pri‐ marily using verbs in the objective case这段话人类理解起来比较简单,但是web scraper会认为objective是一样的,且出现了4次。
宾夕法尼亚大学开发了名为Penn Treebank Project标签系统用以标注句子里每个单词的类型,比如是动词还是名字等。我们来看一个简单的例子,在nltk里,我们import pos_tag
1
2
3
4
5
6
7
8
from nltk import word_tokenize,Text,pos_tag
from nltk.book import *
text = word_tokenize("The dust was thick so he had to dust")
print(pos_tag(text))
# output
# [('The', 'DT'), ('dust', 'NN'), ('was', 'VBD'), ('thick', 'RB'), ('so', 'RB'), ('he', 'PRP'), ('had', 'VBD'), ('to', 'TO'), ('dust', 'VB')]
在The dust was thick so he had to dust这句话里,每一个单词都转换成一个包含tag的tuple。比如('was', 'VBD')中的VBD表示”过去式动词(Verb,past tense)”。我们来看两个dust,('dust', 'NN')和('dust', 'VB')分别被tag上了NN(Noun)和VB(Verb)。是不是很神奇呢。NLTK用一种称为context-free grammar(本质上是一套用以决定哪种词性的单词可以跟在哪种词性的单词后面的规则)来判断单词的tag。
那么我们来看看,这对于web scraper有什么用呢?请看下面搜索场景:
-
你想从一个网站上提取google这个单词作为名词而不是动词的所有例子;
-
你想搜索Google但是大小写都要。
这个时候 pos_tag就派上大用场了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from nltk import word_tokenize,sent_tokenize,pos_tag
sentences = sent_tokenize("google is one of the best companies in the world. I constantly google myself to see what I'm up to.")
nouns = ['NN','NNS','NNP','NNPS']
for sentence in sentences:
if "google" in sentence.lower():
taggedWords = pos_tag(word_tokenize(sentence))
for word in taggedWords:
if word[0].lower() == "google" and word[1] in nouns:
print(sentence)
# output
# google is one of the best companies in the world.
这里我们将google作为名词的句子打印出来。
很多自然语言的ambiguity可以被NLTK的pos_tag解决。利用单词+tag而不仅仅是单词将会让你Web Scraping text的有效性和准确性大大提高。
4 其他资源
以下两本书都是基于NLTK的比较全面介绍自然语言的经典书籍,如果有兴趣可以看看。
-
《Natural Language Processing with Python》 by Steven Bird, Ewan Klein and Edward Loper;
-
《Natural Language Annotations for Machine Learning》 by James Pustejovsky and Amber Stubbs;
5 总结
自然语言的处理,分析和理解是计算机科学挑战最大的话题之一。本文第一部分介绍了三个自然语言的实例:
-
生成文章的summary:通过n-grams剔除无意义的词,再取里面比如前5个频率最高的n-grams,然后找出文中第一次出现每个n-grams的句子,组合在一起,就是一段稍显粗糙的summary。
-
马尔科夫模型生成句子:通过将文章里的单词和标点分成独立的item,且记录下在每个item后面跟随的item出现频率,通过马尔科夫模型生成随机出现在某item后面的item,循环n次,就能生成一段带有原始文章气质的n个单词的句子。
-
六度维基理论:通过有向图的宽度搜索,我们利用已经存储在mysql数据库里的pages和links两个table,来搜索Kevin Bacon到目标的link path。
本文第一部分只是从概率角度来分析词频,并没有触及单词的真正意思(比如词性)。第二部分我们用NLTK的tag来标注每个单词在句子里的词性。主要涉及了NTLK的两个功能:
-
统计分析:text object,frequency distribution,ngrams;
-
辞典学分析:用tag来标注词性,结合Web Scraper来找出某个单词的动词(剔除名词)的例子。例如在一段落里找出google作为名词而不是动词的句子集合。
最后我们将本文整理成下图以供参考。