目录
在《Web Scraping With Python》第一部分,Basic Srapers,我们覆盖了Web Scraping的基础部分,即如何获取数据,解析数据和存储数据。之所以说它是基础,是因为获取的数据都是整理好存储在既定格式(如html,xml,json,doc,txt,pdf,csv等)里的;并且我们没有涉及到反爬虫程序(antiscraping measures),JavaScript,登录表格,流数据等话题。第二部分,Advanced Scraper,我们就来关注这些Advanced的话题。
首先,本文作为第二部分Advanced Scraper的第1篇笔记,我们来了解下如何从将原始数据清理,规范化以成为我们需要的数据,即数据清理。
1 介绍
Dirty Data:badly-formatted data,due to errant punctuation, inconsistent capitalization, line breaks, and misspellings。Well-formatted data is are and most of time, you will encounter the Dirty Data。
2 Cleaining in Code
这里我们通过Wikipedia的html读成字符串来提取相邻两个单词的组合。在这过程中,我们通过三步来清理dirty data:
- 读取原始数据;
- 比如用空格分离单词前,需要将单词之间的空格规范好;
- 单词分离后要对包含不合格字母(比如0-9)的单词条目进行剔除。
2.1 Raw Data:用空格来分离单词
repr(): for unambiguous;
str(): for readbility;
print(obj):prints str(obj);
print(collection):each obj within the collection is printed with repr(obj).
Thus, theprint(ngram)prints the repr(string1) and repr(string2), such as newline(for str) to\n(for repr).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from urllib.request import urlopen
from bs4 import BeautifulSoup
def ngrams(input,n):
input = input.split(' ') #通过软空格' '来分离字符串成单词。
output = []
for i in range(len(input)-1+n):
output.append(input[i:i+n])
return output
htmlFile = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(htmlFile.read(),"html.parser")
content = bsObj.find("div",{"id":"mw-content-text"}).get_text()
ngrams = ngrams(content,2)
for ngram in ngrams:
print(ngram)
# Output
# ['This', 'article']
# ['article', 'is']
# ...
# ['Foundation', 'License\n\n\nFilename']
# ['License\n\n\nFilename', 'extensions\n.py,']
# ['27\xa0June', '2016;']
2.2 Filter
2.2.1 string按空格分离成word
这里包括了7,411 2-grams且其中有很多诸如换行符\n,硬空格\xa0等转义字符集(excape characters)。我们可以进一步用正则表达式去清理。
硬空格(\xa0):编辑器会在软空格(0x20)处选择性换行来适应屏幕的显示。但是有时候你不希望例如
100 km的空格被换行使得100出现在第一行行尾,km出现在第二行行首。这个时候你就需要在100与km之间将软空格0x20换成硬空格\xa0。最后的结果是100 km要么显示在第一行行尾,要么显示在第二行行首,而不会中间断开。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
...
def ngrams(input,n):
#保证所有相邻字母之间只有1个空格
input = re.sub('\n+', ' ', input) #多个换行符'\n' 变1个空格
input = re.sub(' +', ' ', input) #多个空格 变1个空格
input = re.sub('\xa0+', ' ', input) #多个硬空格\xa0 变1个空格
input = re.sub('\[[0-9]*\|,]','',input) #将引用[3] 变无
input = input.split(' ')
output = []
for i in range(len(input)-1+n):
output.append(input[i:i+n])
return output
...
#Output
# ['This', 'article']
# ['article', 'is']
# ...
# ['Python', '3.5)[5]']
# ['Lisp,[16]', 'Modula‑3,[11]']
# ...
# 总结成
# ['Pythoneers.[43][44]', 'Syntax'], ['7', '/'], ['/', '3'], ['3', '=='], ['==', '2']
2.2.2 标点; word清理
输出的结果里还有数字,标点符号等,我们需要进行二次清理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import string
...
def cleanInput(input):
#保证所有相邻字母之间只有1个空格
input = re.sub('\n+', ' ', input) #多个换行符'\n' 变1空格
input = re.sub('\[[0-9]*\|,]','',input) #将引用[2]等 变无
input = re.sub(' +', ' ', input) #多个空格 变1空格
input = re.sub('\xa0+', ' ', input) #多个硬空格\xa0 变1空格
input = input.split(' ')
cleanInput = []
for item in input:
item = item.strip(string.punctuation)
if(len(item) > 1) or (item.lower() == 'a') or item.lower() == 'i':
cleanInput.append(item)
return cleanInput
...
def ngrams(input,n):
input = cleanInput(input)
output = []
for i in range(len(input)-1+n):
item = input[i:i+n]
if excludeDigits(item) and excludeHref(item):
output.append(item)
return output
...
#Output
# ['This', 'article']
# ['article', 'is']
# ['is', 'about']
# ['about', 'the']
# ['the', 'programming']
# ['programming', 'language']
# ['language', 'For']
# ...
现在输出就是比较完美的n-grams格式了。
2.3 Data Normalization
数据库规范化(Data Normalization):数据库设计中的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。
n-grams例子中我们获取的数据有很多重复的条目,比如有多个['Software', 'Foundation']。我们可以通过数据库规范化来将频数加入到['Software', 'Foundation'],使得我们的数据库信息并没有减少,但是需要的存储空间却少了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import collections.OrderedDict
...
def ngrams(input,n):
input = cleanInput(input)
output = dict()
for i in range(len(input)-1+n):
item = ' '.join(input[i:i+n])
if excludeDigits(item) and excludeHref(item):
if item in output:
output[item] += 1
else:
output[item] = 1
return output
htmlFile = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(htmlFile.read(),"html.parser")
content = bsObj.find("div",{"id":"mw-content-text"}).get_text()
ngrams = ngrams(content,2)
#ngrams是一个dictionary, 根据其value来排序(sorted,返回一个list),排完之后按顺序插入OrderedDict
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda item: item[1], reverse=True))
for k,v in ngrams.items():
print(k,v)
#Output
# Software Foundation 37
# Python Software 37
# of Python 36
# of the 34
# Foundation Retrieved 32
# ...
上述代码关键有两点需要注意:
-
我们在
def ngrams(input,n)里将item存储成Dictionary,key是item自己,value是出现的次数。 -
我们将无序的字典Dictionary排序成list后转成有序的字典OrderedDict。由于Dicitonary key的哈希的特性,因此是无序的。要转换Dictionray至OrderedDictionary,并且按照出现的频数降序排列,可以将Dictionary先通过
sorted()转成list,再转成OrderedDictionary。
3 Cleaining with App: OpenRefine
以上部分Cleaning in code是几乎我们能用代码进行数据清理的最大程度了,即在code里对原始数据:
- 清理不规范的数据,转成我们想要的类型;
- 规范化数据库,去除冗余信息。
以上是对于自己熟悉的数据进行的处理,但是对于不是你自己创建的数据库,或者在没有视觉上看到该数据库之前你不知道如何清理的数据库,我们要怎么清理呢。这个时候google的一个软件OpenRefine可以give you a hand。
OpenRefine: a standalone open source desktop application for data cleanup and transformation to other formats.
openRefine有两个data cleanup的主要功能:
-
Filtering,过滤某一Field对应的条件的Row,比如正则表达式;Facets,include或者excludeField枚举值对应的条件的Row,例如Year下有各种年份,我们include2000就只展现Year=2000的Row;
-
Cleaning,变换transform某一Field下不合规范的数据,例如将Year下2000-1-20等变换成2000,则需要输入GREL(Google Refine Language)正则表达式
value.match(".*([0-9]{4}).*").get(0)。
具体使用请参见OpenRefine。
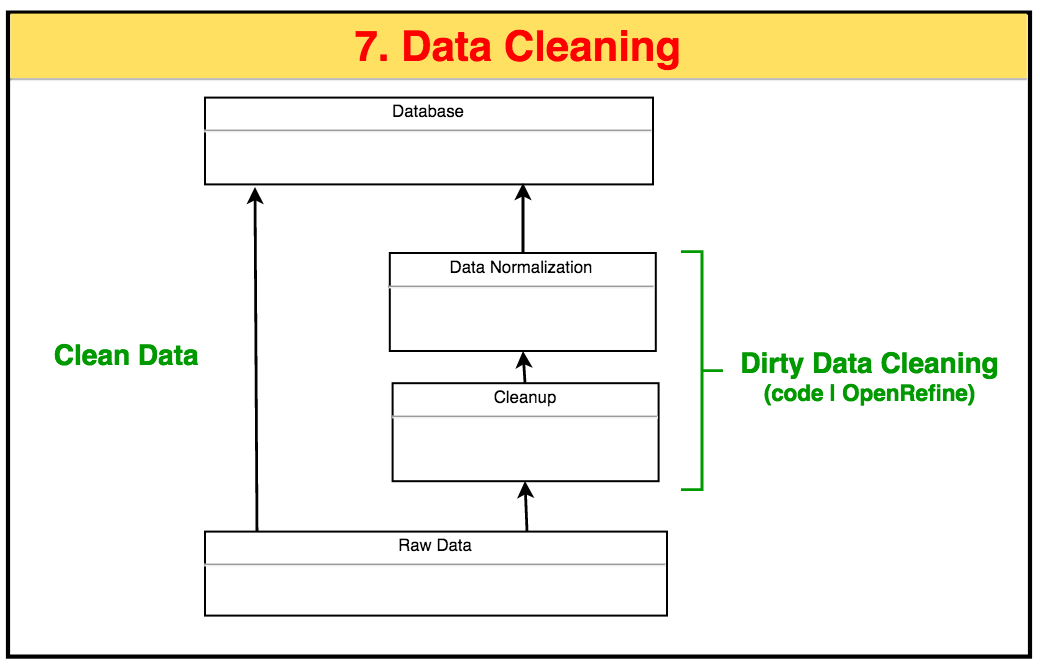
4 总结
本文展示了如何将原始数据转换成规范化数据库,通过代码和OpenRefine两种途径。最后总结成下图以供参考。