
目录
上篇文章我们已经介绍过如何将数据存储到Media File,CSV,MySQL。本文我们来看看如何对文档(Docuement)进行阅读。
Internet不仅仅是由网页(HTML文件)构成,还包括其他在Internet上传输和存储的数据,比如text,PDF,images, video, email等。在1992年HTML发明之前,网页还不存在;在那之后,HTML文件本质上只是展示网页数据的一个外壳,真正传输网页数据的比如有XML,JSON等数据格式。
在这篇笔记里,我们将text,PDF,CSV,doc && docx,images,audio,video等包含信息的文件类型在这里统称为文档(Documents)。
1 Document Encoding
文档编码(Document Encoding):每种文档的文件类型都是由其扩展名确定的,这扩展名是对以0与1存储的最基本数据的编码(包括每个字符是多少byte等)。
2 Different Documents
2.1 Text
文本文档(.txt):只包括字符的文档,需要指定字符集(Character Set)来阅读。用错了字符集会出现乱码。
对文本文档,我们可以直接阅读,用.read(),而不用像HTML一样用,需要先转换成BeautifulSoup实例。
1
2
3
4
5
6
7
8
from urllib.request import urlopen
textFileHandler = urlopen("http://www.pythonscraping.com/pages/warandpeace/chapter1.txt")
textContent = textFileHandler.read()
print(textContent)
Output:
# b'CHAPTER I\n\n"Well, Prince, so Genoa and Lucca
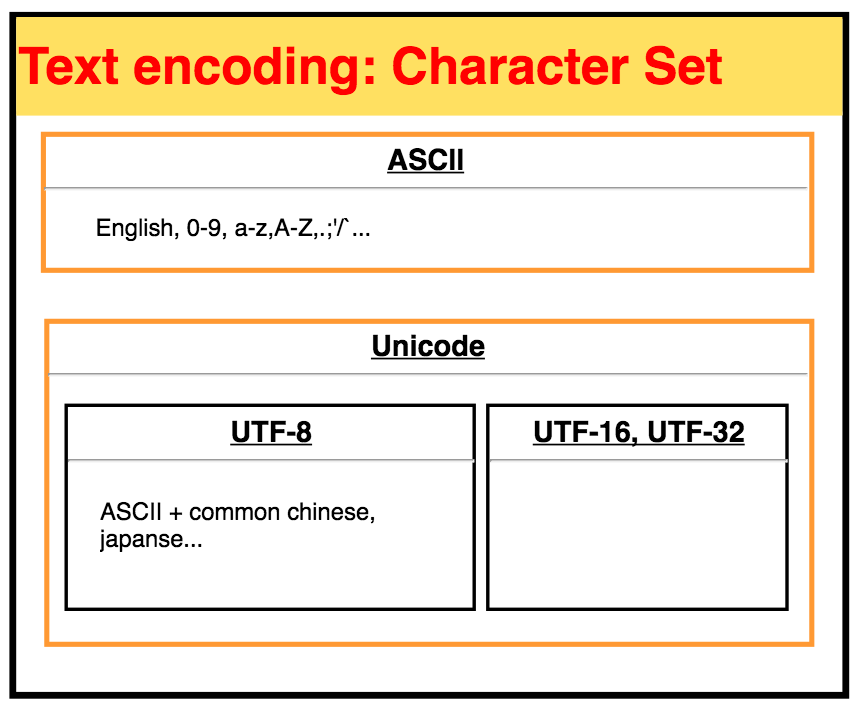
但是对于文本文档只知道其扩展名是不够的,还需要知道其字符集(Character Set)才能正确阅读。用错了字符集会出现乱码码。现在常用的字符集分为两种:
-
ASCII:制定于1960s,1 byte(8 bits),只用了7bits,0-127个数字代表128个字符,包括
0-9,a-z,A-Z,,./<>?;':"[]\{}|`~!@#$%^&*()_+=-等。对于英语来说,已经够用了。 -
Unicode:制定于1990s,4 byte(32 bits);由于ASCII表示不了其他语言,比如汉字有10万个(常用6000个),日语等,所以定制了Unicode。但是32bits里面大部分都用不到造成空间浪费,所以取里面常用的制定了不同的标准,比如UTF-8,UTF-16,UTF-32等。其中以UTF-8最为常用。
ASCII,Unicode,UTF-8之间的关系见下图。
UTF-8: a character encoding with variable-length and 8-bit code units,capable of encoding all possible characters defined by Unicode. UTF-8 is the dominant character encoding for the World Wide Web, accounting for 87.2% of all Web pages in July 2016。
对于上面的代码,由于.txt文件是ASCII,而python的默认字符集也是ASCII代码,因此输出是正确的,不会出现乱码。但是我们看下用同样代码运行UTF-8编码的.txt文件,会有什么情况。
1
2
3
4
5
6
7
8
from urllib.request import urlopen
textFileHandler = urlopen("http://www.pythonscraping.com/pages/warandpeace/chapter1.txt")
textContent = textFileHandler.read()
print(textContent)
#Output:
# b"\xd0\xa7\xd0\x90\xd0\xa1\xd0\xa2\xd0\xac
没错,你看到输出是不对的。这个时候我们需啊将print(textContent)改成print(str(textContent,'UTF-8'))即可。
如果结合BeautifulSoup,则代码类似下面。
1
2
3
4
5
6
7
8
9
10
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html,"html.parser")
content = bsObj.find("div", {"id":"mw-content-text"}).get_text()
content = bytes(content, "UTF-8") #先转回二进制数
content = content.decode("UTF-8") #再用UTF-8解码
print(content)
你或许会问,如何知道某些网站的字符集是什么呢?通常在HTML会显示如<meta charset="utf-8" />的信息,表示字符集。因此我们可以根据HTML文件来判断如何解码text。
2.2 CSV
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from urllib.request import urlopen
import csv
from io import StringIO
csvFileHandler = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv")
csvString = csvFileHandler.read().decode("ascii",'ignore')
#创建StringIO实例(内存中读写字符串),该实例和fileHandler类似,因此可以在使用fileHandler的地方使用StringIO实例。
memory = StringIO(csvString)
csvReader = csv.reader(memory) #csv.reader(memory) 返回一个Iterator,每一个item是list
for row in csvReader:
print(row)
# Output:
# ['Name', 'Year']
# ["Monty Python's Flying Circus", '1970']
# ['Another Monty Python Record', '1971']
我们可以将row以更友好的方式展现,因为row是list,所以可以用下标访问其中元素。
1
2
3
4
5
6
7
for row in csvReader:
print("The album \"" + row[0] + "\" was relased in "+ row[1])
# Output:
# The album "Name" was relased in Year
# The album "Monty Python's Flying Circus" was relased in 1970
# The album "Another Monty Python Record" was relased in 1971
但是第一行的[‘Name’, ‘Year’]也被更改了,如何防止呢。可以用DictReader。
1
2
3
4
5
6
7
8
csvReader = csv.DictReader(memory)
for row in csvReader:
print(row)
# Output:
# {'Name': "Monty Python's Flying Circus", 'Year': '1970'}
# {'Name': 'Another Monty Python Record', 'Year': '1971'}
# {'Name': "Monty Python's Previous Record", 'Year': '1972'}
2.3 PDF
PDF:a file format used to present documents in a manner independent of application software, hardware, and operating systems.[2] Each PDF file encapsulates a complete description of a fixed-layout flat document, including the text, fonts, graphics, and other information needed to display it。
PDFMiner3K:a tool for extracting information from PDF documents. Unlike other PDF-related tools, it focuses entirely on getting and analyzing text data. location of text in a page, as well as other information such as fonts or lines. It includes a PDF converter that can transform PDF files into other text formats (such as HTML). It has an extensible PDF parser that can be used for other purposes than text analysis。
下面是读取pdf的一段代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.layout import LAParams
from pdfminer.converter import TextConverter
from io import StringIO
def readPDF(pdfFile):
resourceManager = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(resourceManager,retstr,laparams=laparams)
process_pdf(resourceManager,device,pdfFile)
device.close()
content = retstr.getvalue()
retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/pages/warandpeace/chapter1.pdf")
# you can change the pdfFile from local path
# pdfFile = open("chapter1.pdf",'rb')
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
# Output:
# CHAPTER I
#
# "Well, Prince, so Genoa and Lucca are now just family estates of
# theBuonapartes. But I warn you, if you don't tell me that this
2.4 doc && docx
Word Document(.doc,.docx):python-docx library只能进行创建.docx,读取基本文档元信息,而不是文档内容。为了获取文档内容的信息,我们只能按下面的方法,先将.docx转成Byte,然后解压,最后读取。
请看代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from urllib.request import urlopen
from zipfile import ZipFile
from io import BytesIO
wordFileHandler = urlopen("http://pythonscraping.com/pages/AWordDocument.docx")
wordFileString = wordFileHandler.read() #read String from wordFielHandler
worldFielByte = BytesIO(wordFileString) #turn String into Bytes
docuement = ZipFile(worldFielByte) #unzip it, because all the .docx are zipped to save space,return a fileHandler
xml_content = docuement.read('word/document.xml') #read the unzipped file into String for name 'word/document.xml'
print(xml_content.decode('utf-8'))
# Output:
# <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
# <w:document xmlns: /w:pPr><w:r><w:t>A Word Document on a Website</w:t></w:r><w:bookmarkStart w:id="0" w:name="_GoBack"/><w:bookmarkEnd w:id="0"/></w:p><w:p w:rsidR="00764658" w:rsidRDefault="00764658" w:rsidP="00764658"/><w:p w:rsidR="00764658" w:rsidRPr="00764658" w:rsidRDefault="00764658" w:rsidP="00764658"><w:r><w:t>This is a Word document, full of content that you want very much. Unfortunately, it’s difficult to access because I’m putting it on my website as a .</w:t></w:r><w:proofErr w:type="spellStart"/><w:r><w:t>docx</w:t></w:r><w:proofErr w:type="spellEnd"/><w:r><w:t xml:space="preserve"> file, rather than just publishing it as HTML</w:t></w:r></w:</w:document>
输出有很多内容,.docx的文本被镶嵌在每一个<w:t>tag里,因此可以很容易用BeautifulSoup获取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from urllib.request import urlopen
from zipfile import ZipFile
from io import BytesIO
from bs4 import BeautifulSoup
wordFileHandler = urlopen("http://pythonscraping.com/pages/AWordDocument.docx")
wordFileString = wordFileHandler.read() #read String from wordFielHandler
worldFielByte = BytesIO(wordFileString) #turn String into Bytes
docuement = ZipFile(worldFielByte) #unzip it, because all the .docx are zipped to save space
xml_content = docuement.read('word/document.xml') #read the unzipped file into string,存储为word/document.xml文件。
bsObj = BeautifulSoup(xml_content,'html.parser') #BeautifulSoup也可以用来解析XML
texts= bsObj.findAll("w:t")
for text in texts:
print(text.get_text())
# Output:
# A Word Document on a Website
# This is a Word document, full of content that you want very much. Unfortunately, it’s difficult to access because I’m putting it on my website as a .
# docx
# file, rather than just publishing it as HTML
由于.docx被认为是拼写错误,被<w:proofErr w:type="spellStart"/>Tag包裹,因此输出有稍许不同。
我们来尝试打印该.docx文档的标题。我们观察到title的父亲的兄弟的孩子在<w:pstyle w:val="Title">tag里,因此可以遍历来找到title。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
...
bsObj = BeautifulSoup(xml_content,'html.parser') #BeautifulSoup也可以用来解析XML
textTags= bsObj.findAll("w:t")
for textTag in textTags:
try:
titleTag = textTag.parent.previousSibling.find("w:pstyle",{"w:val": "Title"})
if titleTag is not None:
print("<h1>",textTag.text,"</h1>")
except AttributeError:
pass
# Output:
# <h1> A Word Document on a Website </h1>
3 总结
最后将本文总结成下图。 reading document summary

4 Web Scraping Part I:Basic Scrapers 总结
到此为止,我们的WebScraping系列的第一部分,Basic Scrapers就已经全部结束。通过这6篇笔记,相信您对Web scraping已经有了一个初步的了解,比如如何获取数据(Retrieve Data),解析不同文件类型的数据(Parse Data, includes html,xml,txt,pdf,csv,doc&docx等)。我们将本部分总结成下图以供参考。

