
目录
本系列1-4篇笔记集中讲解如何获取数据,包括BeautifulSoup和API的单独使用以及混合使用。对于如何使用数据,仅限于在终端打印。但是如果缺少了数据的存储和分析,Web Scraping的实用性就大打折扣。本文我们来介绍三种自动数据存储(Automated Data Storage)的方法,即Media Files,CSV,MySQL。
1 Media Files
多媒体文件(Media Files):主要包括音频,视频,图片。
通常有两种方法存储多媒体文件:
-
By reference:仅需要存储Medial File的URL。优点是Scraper运行更快,不需要下载文件;程序更简单;服务端压力更小。缺点是受制于人,任何URL源的改变,都会影响Scraper的运行;且实际上真实的Browser浏览网页时会下载所有的需要的assets。因此下载Media File会让Scraper运行时更像一个真实的人在用Browser浏览网页。
-
By downloading the file iteself:下载Media File到本地。优缺点和By Reference相反。
那么问题来了,多媒体存储哪家强?如果需要多次访问Media File,则用后者(大部分实际情况);如果只需要单次获取表面信息。
2.1 Download a Single Internal File
1
2
3
4
5
6
7
8
9
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
htmlHandler = urlopen("http://www.pythonscraping.com")
bsObj = BeautifulSoup(htmlHandler.read(),"html.parser")
imageUrl = bsObj.find("a",{"id": "logo"}).find("img").attrs["src"]
urlretrieve(imageUrl, "logo.jpg") #a URL, filename in the same directory that the script is running from
2.2 Download All Internal Files
上述代码对于已知file的扩展名有效。但是大部分情况是你不知道。以下代码将会下载某一页面all internal files(with src attribute)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import os
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
downloadDirectory = "downloaded"
baseUrl = "http://pythonscraping.com"
def getAbsoluteURL(baseUrl,source):
'''
:param baseUrl:
:param source: http://www.pythonscraping.com/misc/jquery.once.js?v=1.2
:return: http://pythonscraping.com/misc/jquery.once.js?v=1.2
'''
if source.startswith("http://www."): #去掉www
url = "http://"+source[11:]
elif source.startswith("http://"): #已经去掉www,则不变
url = source
elif source.startswith("www."): #若www.开头,则加http://并去掉www
url = "http://"+source[4:]
else:
url = baseUrl + "/" + source #若部分url,则补全
if baseUrl not in url: #去掉外部链接
return None
return url
def getDownloadPath(baseUrl,absoluteUrl,downloadDirectory): #dwonloadDirectory是script目录下的文件夹,
'''
:param baseUrl:
:param absoluteUrl: http://pythonscraping.com/misc/jquery.once.js?v=1.2
:return: downloaded/misc/jquery.once.js?v=1.2
'''
path = absoluteUrl.replace("www.","")
path = path.replace(baseUrl,"")
path = downloadDirectory+path
directory = os.path.dirname(path)
if not os.path.exists(directory):
os.makedirs(directory)
return path
htmlHandler = urlopen("http://www.pythonscraping.com")
bsObj = BeautifulSoup(htmlHandler.read(),"html.parser")
downloadList = bsObj.findAll(src=True) #this is a lambda expression to select all tag with src attribute.
for download in downloadList:
fileUrl = getAbsoluteURL(baseUrl,download.attrs["src"])
if fileUrl is not None:
print(fileUrl)
urlretrieve(fileUrl, getDownloadPath(baseUrl,fileUrl,downloadDirectory))
我们来分析下代码。
上述代码不需要知道具体src文件对应的扩展名,只需要将src作为filename的一部分统一处理成文件目录,然后循环下载即可。其中bsObj.findAll(src=True)是一个lambda expression用来筛选所有有src属性的Tag;getAbsoluteURL(baseUrl,source)normalize the source url as absolute url;getDownloadPath将absolute url换成script下的文件目录(若不存在则创建);osmodule属于Python的core library,作为Python和operating system的interface。
2 CSV
CSV(comma-sparated values):是用来存储 spreadsheet data最流行的文件格式。由于其简单性,被诸如Microsoft Excel等许多应用程序所使用。一个简单的CSV例子如下:
fruit,cost
apple,1.00
banana,0.30
pear,1.25
每一row都被newline字符界定。在任意row里,columns被commas(,)分开。有一些其他格式的CSV使用tabs或者其他字符来代替,,但是使用比较少。
如果你只需要下载一个现成的CSV文件,只需要和第一部分的代码一样即可。我们这里来看看如何修改或者生成一个CSV文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import os
import csv
def getCSVPath(directory,filename):
if not os.path.exists(directory):
os.makedirs(directory)
return os.getcwd()+"/"+directory+"/" + filename
path = getCSVPath("CSV","test.cv")
try:
csvFileHandler = open(path,'w+') #file handler
writer=csv.writer(csvFileHandler)
writer.writerow(('number', 'number puls 2', 'number times 2'))
for i in range(10):
writer.writerow((i,i+2,i*2))
finally:
csvFileHandler.close()
#Output:
# number,number puls 2,number times 2
# 0,2,0
# 1,3,2
# 2,4,4
# 3,5,6
# 4,6,8
# 5,7,10
# 6,8,12
# 7,9,14
# 8,10,16
# 9,11,18
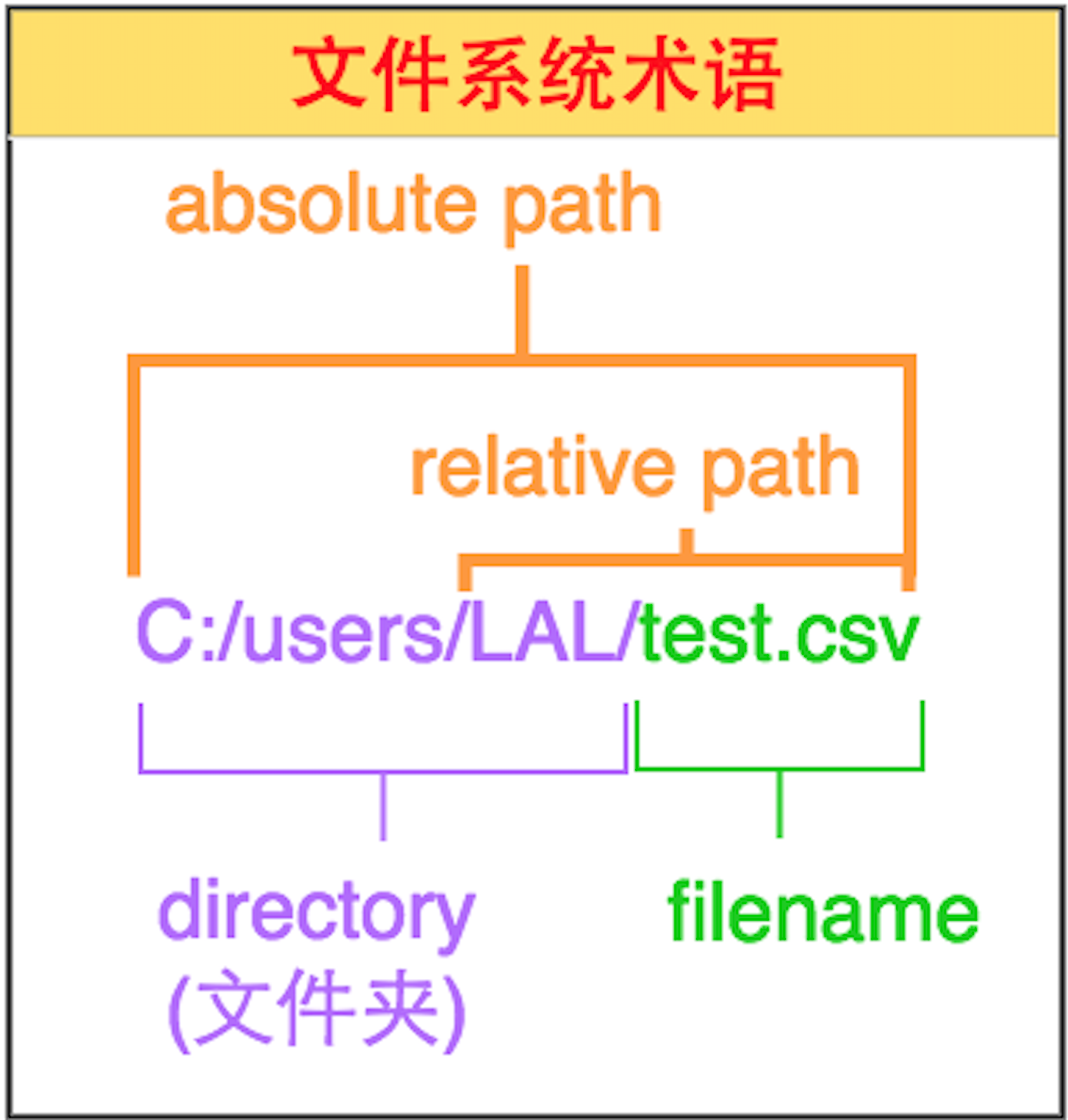
关于directory,filename,path(absolute,relative)的区别请见下图。
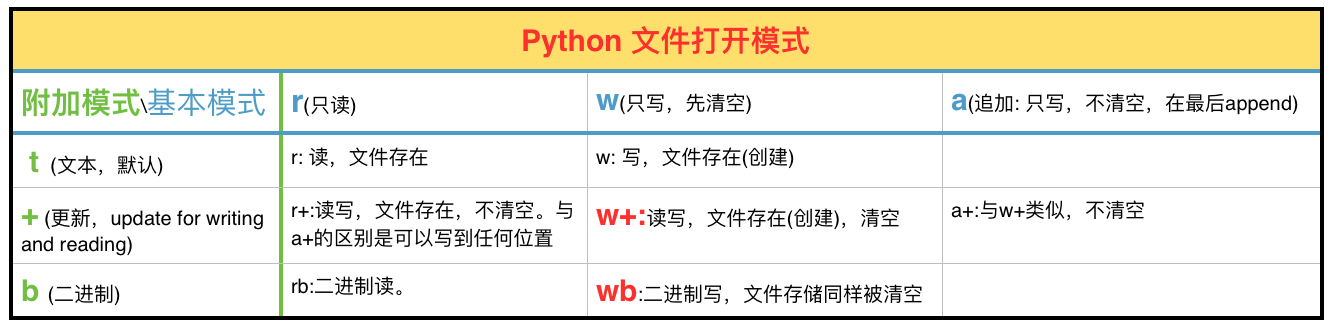
Python文件的打开模式有主要9种,w+表示可读写,先清除原来内容。
一个常见的Web Scraping任务是获得HTML table里的数据,然后写进CSV文件。Wikipedia Comparsion of Text Editors提供了一个相当复杂的table,我们尝试用BeautifulSoup和csv module将其写入csv文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import os
import csv
from bs4 import BeautifulSoup
from urllib.request import urlopen
def getCSVPath(directory,filename):
if not os.path.exists(directory):
os.makedirs(directory)
return os.getcwd()+"/"+directory+"/" + filename
htmlFileHandler = urlopen("https://en.wikipedia.org/wiki/Comparison_of_text_editors")
bsObj = BeautifulSoup(htmlFileHandler.read(),"html.parser")
tableTag = bsObj.findAll("table",{"class":"wikitable"})[0]
rowTags = tableTag.findAll("tr")
path = getCSVPath("CSV","test.cv")
try:
csvFile = open(path,'w+')
writer=csv.writer(csvFile)
for rowTag in rowTags:
csvRow=[]
for cell in rowTag.findAll(('td','th')): #输出所有的td或者th Tag
csvRow.append(cell.string)
writer.writerow(csvRow)
finally:
csvFile.close()
本部分总结成一张小图。

3 MySQL
MySQL:开放源代码的关系数据库管理系统(relational database management system)。关系数据库(relational database)指比如user A goes to place B,则user A可以在users table里找到,place B可以在places table里找到。MySQL是一个非常适合Web Scraping的数据库,我们会在本系列中用到它!
3.1 安装和入门
请戳我。
3.3 Integrating with Python
Python的pymysql module是MySQL在Python上实现的客户端。 使用pip命令行安装pymysql module非常方便。
1
pip3 install PyMySQL
这里pip3表示安装在python3的库里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import pymysql
#1.1 create connection object
connection = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',user='root',password='*****',db='mysql')
#1.2 create cursor object
cursor = connection.cursor()
#2.1 xecyte SQL
cursor.execute("USE scraping")
cursor.execute("SELECT * FROM pages WHERE title LIKE 'title%'")
#2.2 获取data
for row in cursor.fetchall():
print(row)
#3.1 close cursor
cursor.close()
#3.2 close connection
connection.close()
#Output:
# (4, 'title1', 'content1', datetime.datetime(2016, 7, 20, 17, 32, 36))
# (5, 'title2', 'content2', datetime.datetime(2016, 7, 20, 17, 32, 36))
# (6, 'title6', 'content6', datetime.datetime(2016, 7, 20, 17, 55, 35))
# (7, 'title7', 'content7', datetime.datetime(2016, 7, 20, 17, 55, 35))
我们可以用之前Wikipedia的Kevin Bacon页面,进行single domain random walk,并且将每个page的title和content(first paragraph)记录在MySQL里。以下是代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import pymysql
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
connection = pymysql.connect(host ='127.0.0.1',
unix_socket='/tmp/mysql.sock',
user ='root',
password ='******',
charset ='utf8')
cursor = connection.cursor()
cursor.execute("USE scraping")
random.seed(datetime.datetime.now())
def store(title, content):
'''
:param title: if title already exist, return, else store
:param content:
:return:
'''
#use encaosulate string with \"%s\" tackles the NULL tiltle(otherwise error appear), why?
cursor.execute("SELECT * FROM pages WHERE title=\"%s\"", title)
if(len(cursor.fetchall()) > 0):
return;
else:
# the title and content should be 'title' and 'content' in the
cursor.execute("INSERT INTO pages (title,content) VALUES (\"%s\",\"%s\")",(title,content))
cursor.connection.commit()
def getLinks(articalUrl):
htmlFileHandler = urlopen("https://en.wikipedia.org" + articalUrl)
bsObj = BeautifulSoup(htmlFileHandler.read(),"html.parser")
title = bsObj.find("h1",{"id":"firstHeading"}).string
content = bsObj.find("div",id="mw-content-text").find('p').get_text()
print(content[0:100])
store(title, content[0:100])
return bsObj.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
try:
while(len(links)>0):
newArticleHref = links[random.randint(0,len(links)-1)].attrs["href"]
print(newArticleHref)
getLinks(newArticleHref)
finally:
cursor.close()
connection.close()
#Output:
# +-----+------------------------------+------------------------------------------------------------------------------------------------------------------+---------------------+
# | id | title | content | created |
# +-----+------------------------------+------------------------------------------------------------------------------------------------------------------+---------------------+
# | 119 | 'Kevin Bacon' | 'Kevin Norwood Bacon (born July 8, 1958)[2] is an American actor and musician whose films include ' | 2016-07-20 22:18:52 |
# | 120 | 'Kathleen Quinlan' | 'Kathleen Denise Quinlan (born November 19, 1954) is an American film and television actress. She rec' | 2016-07-20 22:18:54 |
# | 121 | 'Andrew Lincoln' | 'Andrew James Clutterbuck (born 14 September 1973),[1] better known by his stage name Andrew Lincoln,' | 2016-07-20 22:19:00 |
# | 122 | 'Kevin Costner' | 'Kevin Michael Costner (born January 18, 1955) is an American actor, film director, producer, musicia' | 2016-07-20 22:19:03 |
# | 123 | 'Jamie Foxx' | 'Eric Marlon Bishop (born December 13, 1967),[1] known professionally by his stage name Jamie Foxx, i' | 2016-07-20 22:19:07 |
# | 124 | 'Ménage à trois' | 'A ménage à trois (French for "household of three") is a domestic arrangement in which three people h' | 2016-07-20 22:19:08 |
# | 125 | 'He Said, She Said' | 'He Said, She Said is a 1991 American romantic comedy directed by Ken Kwapis and Marisa Silver and st' | 2016-07-20 22:19:09 |
# +-----+------------------------------+------------------------------------------------------------------------------------------------------------------+---------------------+
3.4 Database Techniques and Good Practice
数据库是计算机科学的一门重要的研究领域,许多人究其一生来研究数据库。你我或许不是这样的研究者,但是有以下几点建议可以让你的数据库运行的更加快速。
-
在大部分情况下,增加一个id column 作为PRIMARY KEY,并且设置为AUTO_INCREMENT;
-
使用智能索引。举个例子,在字典里,每一个条目是按照单词从a-z顺序排列,而不是单词的定义;实际使用中,我们肯定会用前者去查条目。但是在计算机领域,使用后者的场景并不少见;试想一下,给你一个定义,按一下命令去查找条目
SELECT * FROM dictionary WHERE definition="A small furry animal that says meow";这样的查找效率就比较低下。实际上,你可以让MySQL给定义的前10个字符创建索引CREATE INDEX definition ON dictionary (id, definition(16));,这样搜索起来就快多了并且不会增加太多空间负担。 -
将一个Table拆分成多个Table存储以减少存储空间。
-
除非使用第三方日志模块,你很难去获取Row怎删改查的时间,所以记得给Table加一个
createdTime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMPField。
3.5 “Six Degrees” in MySQL
我们之前在第三篇笔记里提到的”Six Degree of Wikipedia”问题,可以在这里利用数据库来存储小于6个点的信息。话不多说,上代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
from urllib.request import urlopen
import pymysql
from bs4 import BeautifulSoup
import re
connection = pymysql.connect(host ='127.0.0.1',
unix_socket='/tmp/mysql.sock',
user ='root',
password ='******',
charset ='utf8')
cursor = connection.cursor()
cursor.execute("USE wikipedia")
def insertPageIfNotExists(url):
'''
:param url: if url already exist, return its id; else insert first, then return its id
:return: id
'''
#use encaosulate string with \"%s\" tackles the NULL tiltle(otherwise error appear), why?
cursor.execute("SELECT * FROM pages WHERE url=%s", url)
if cursor.rowcount == 0:
# the title and content should be 'title' and 'content' in the
cursor.execute("INSERT INTO pages (url) VALUES (%s)", url)
cursor.connection.commit()
return cursor.lastrowid
else:
return cursor.fetchone()[0];
def insertLink(fromPageId,toPageId):
'''
:param fromPageId,toPageId: if (fromPageId,toPageId) not exist, insert into links table
:return:
'''
#use encaosulate string with \"%s\" tackles the NULL tiltle(otherwise error appear), why?
cursor.execute("SELECT * FROM links WHERE fromPageId=%s AND toPageId=%s", (int(fromPageId),int(toPageId)))
if cursor.rowcount == 0:
# the title and content should be 'title' and 'content' in the
cursor.execute("INSERT INTO links (fromPageId,toPageId) VALUES (%s,%s)", (fromPageId,toPageId))
cursor.connection.commit()
else:
return;
pages = set()
def getLinks(pageUrl,recursionLevel):
global pages
# 大于4的pageUrl扔掉
if recursionLevel > 4:
return
pageId = insertPageIfNotExists(pageUrl)
print(pageId,type(pageId))
htmlFileHandler = urlopen("https://en.wikipedia.org" + pageUrl)
bsObj = BeautifulSoup(htmlFileHandler.read(),"html.parser")
linkTags = bsObj.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$"))
for linkTag in linkTags:
linkHref = linkTag.attrs["href"]
insertLink(pageId,insertPageIfNotExists(linkHref))
if linkHref not in pages:
pages.add(linkHref)
getLinks(linkHref,recursionLevel+1)
try:
getLinks("/wiki/Kevin_Bacon",0)
finally:
cursor.close()
connection.close()
#Output:
# mysql> SELECT * FROM pages;
# +----+-----------------------------------------+---------------------+
# | id | url | created |
# +----+-----------------------------------------+---------------------+
# | 1 | /wiki/Kevin_bacon | 2016-07-20 23:11:47 |
# | 2 | /wiki/Kevin_Bacon_(disambiguation) | 2016-07-20 23:12:49 |
# | 3 | /wiki/San_Diego_Comic-Con_International | 2016-07-20 23:24:33 |
# | 4 | /wiki/Comic_Con_(disambiguation) | 2016-07-20 23:24:47 |
# +----+-----------------------------------------+---------------------+
# 3 rows in set (0.00 sec)
#
# mysql> SELECT * FROM links;
# +-----+------------+----------+---------------------+
# | id | fromPageId | toPageId | created |
# +-----+------------+----------+---------------------+
# | 1 | 1 | 2 | 2016-07-20 23:24:24 |
# | 2 | 2 | 1 | 2016-07-20 23:24:25 |
# | 3 | 1 | 3 | 2016-07-20 23:24:33 |
# | 4 | 3 | 4 | 2016-07-20 23:24:47 |
# | 5 | 4 | 3 | 2016-07-20 23:24:48 |
# | 6 | 4 | 5 | 2016-07-20 23:24:48 |
# | 7 | 4 | 6 | 2016-07-20 23:24:48 |
# | 8 | 4 | 7 | 2016-07-20 23:24:48 |
# | 9 | 4 | 8 | 2016-07-20 23:24:48 |
# | 10 | 4 | 9 | 2016-07-20 23:24:48 |
# | 11 | 4 | 10 | 2016-07-20 23:24:48 |
# | 12 | 4 | 11 | 2016-07-20 23:24:48 |
# | 13 | 4 | 12 | 2016-07-20 23:24:48 |
# +-----+------------+----------+---------------------+
4. 总结
最后将本文总结成下图。

