
目录
上篇文章我们已经介绍过BeautifulSoup实战中对多单域名和多域名以及随机抓取和完全抓取等5个任务的实现。本文我们来看看API的单独应用以及如何结合API与BeautifulSoup进行Web Scraping。
1 API
1.1 API概览
应用程序接口(API: Application Programming Interface):不同应用程序及同一应用程序中不同模块之间通讯的标准。API是为了统一软件中不同部分通讯的衔接规范,避免它们之间混乱的通讯。类似与设计模式中的门面模式(fascade)。
虽然API的定义指任何软件,但渐渐的,我们约定俗成认为API是指Web Application API。
API(Web Application API):将网络请求(request)通过HTTP协议经API发送至服务器,然后返回XML或者JSON等格式的数据的过程。
所以从这个角度来说,API其实不是Web Scraping的一部分。因为通常指的Web Scraping是不同过API进行的。但是对网络数据的收集和分析可以将API和Web Scrapingcombine起来,更好的进行我们的所需要的任务。
我们来看下API是如何工作的。实际上,我们可以在浏览器中输入一个简单的API请求,比如http://freegeoip.net/json/50.78.253.58。返回的响应(Response)如下:
{“ip”:”50.78.253.58”,”country_code”:”US”,”country_name”:”United States”,”region_code”:”MA”,”region_name”:”Massachusetts”,”city”:”North Chelmsford”,”zip_code”:”01863”,”time_zone”:”America/New_York”,”latitude”:42.632,”longitude”:-71.3888,”metro_code”:506}
那么问题来了,
同样是在浏览器地址栏中输入,一个API请求和一个常见的Web Address又有什么区别呢:没有太大区别,两者都是通过HTTP协议进行数据传输;唯一的区别是前者返回JSON或者XML文件,而后者返回HTML文件。
见下图。
区别于Web Scraping,API通常有一套标准,包括Common Convetion(Methods,Authentication)和Response。因此只要网络上标准的API,主体上必然满足这样的标准。但是细节上可能有所不同,这个时候,阅读API documentation就必不可少了。
1.1.1 Common Convention
1.1.1.1 Methods
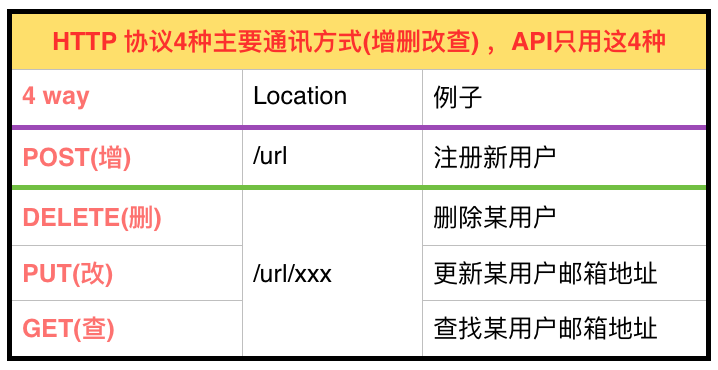
通过HTTP协议请求服务器主要有四种方式,即增删改查:
-
GET(查):当通过浏览器地址栏输入网址或者API请求时(如上例),通过HTTP协议的GET方式进行通信。GET向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
-
POST(增):当填写表格提交(Submit)时,例如注册(Register)或者登入(logo in),你的信息会被送到服务器存储起来。POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
-
PUT(改):用于更新信息,比如用POST注册了新用户,过一段时间想更新邮箱地址,可以用PUT。与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
-
DELETE(删):删除信息,比如删除一个用户。
虽然HTTP还有很多其他通讯方式,以上4种却是所有API涉及到的全部方式。
1.1.1.2 Authentication
API除了以上4种HTTP协议的通讯方式,其授权(Authentication)也是现代API越来越多的一个新加功能。
授权(Authentication):是实名使用API的方式。通常在注册用户名和密码后,系统会生成一个令牌(Token,可能有有效期)。你的任何API的请求都会将令牌作为URL的一部分或者请求头文件里的小甜饼(via a cookie in the request header)发送给服务器。授权的作用是可以追踪用户使用API,限制使用次数,或者通过使用次数进行收费等。
1.1.2 Response:API Calls
正如我们前面提到的,API的响应是返回XML或者JSON格式的文件。两者相比较,JSON更受欢迎:
-
同样内容,JSON比XML大小小近1/3;
-
现代的服务器端的脚本,已经从过去的PHP或者.NET转到如Angular or Backbone等接发API的框架。这些框架更易于处理JSON文件。
一个典型的API Call的格式如下图。

1.2 API实例
1.2.1 Spotify
Echo Nest:MIT开发的一个基于Web Scraping通过人工智能来收集和分析音乐信息(新发布的歌曲,专辑,歌手等)的网站。从2016年开始,Echo Nest被Spotify收购。 Spotify:来自于瑞典的全球最大的流音乐服务商,提供免费(160kb/s + 广告)和付费(通常是$9.99/Month)两种模式的服务,现在全球将近有1亿用户。
关于Spotify的API,这里暂不介绍。
1.2.2 Twitter
Twitter:对其API的使用的保护非常严格。一是Rate Limit,分为1call/min(比如获取某用户的Twitter Followers)和12call/min(比如获取Twitter User的基本信息)两种;二是Authentication来track API的使用情况。
它的使用分为以下2个步骤:
-
获取令牌。
-
应用Twitter API框架。由于Twitter的授权系统建立在比较复杂的OAuth标准上(Authorization的开放网络标准,在全世界得到广泛应用,目前的版本是2.0版),我们用相应的Python框架来应用Twitter API。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from twitter import *
ACCESS_TOKEN = "***"
ACCESS_SECRET = "***"
CONSUMER_KEY = "***"
CONSUMER_SECRET = "***"
t = Twitter(auth=OAuth(ACCESS_TOKEN,ACCESS_SECRET,CONSUMER_KEY,CONSUMER_SECRET))
'''
任务1:搜索tweets
pythonTweets = t.search.tweets(q = "#python")
print(pythonTweets)
'''
'''
任务2:发布Twitter
statusUpdate = t.statuses.update(status="Hello, world!!!")
print(statusUpdate)
'''
'''
任务3:搜索特定用户的tweets
pythonStatuses = t.statuses.user_timeline(screen_name="montypython",count=5)
print(pythonStatuses)
'''
虽然上述3个例子(搜索tweets,发布Twitter,搜索特定用户的tweets)覆盖了绝大部分Twitter API的应用,但是它还拥有许多有用的API,具体可以参见其文档。
1.2.3 Google
当今网络世界,Google犹如一个强大的帝国,控制着几乎网络的方方面面。它拥有各方面巨大的API库:
-
关于各种主题,例如language translation,geolocation,calendars,甚至是geomics等。
-
关于各种应用,例如Gmail,Youtube,Blogger等。
查看Google API通常有两种途径:
-
The Product Page,作为有序的API仓库。
-
The APIs console,用于控制API的开关,查看rate limit和usage,甚至是开启Google-powered云计算。
大部分Google的API都是免费的,但是其搜索引擎的API是收费的(毕竟这是Google的核心嘛)。Google API的rate limit从250/day到20,000,000/day各有不同。如果你用信用卡认证你的身份(Google不会收费),rate limit可以提高10-100倍。
我们来看看使用Google API的步骤:
-
注册Google账号,登录Google Developers Console。创建相应API Key,激活。
-
使用API。
1
2
3
4
5
6
7
//任务1:搜索地址
https://maps.googleapis.com/maps/api/geocode/ json?address=1+Science+Park+Boston
+MA+02114&key=YOUR_API_KEY
//任务2:搜索时区
https://maps.googleapis.com/maps/api/timezone/json?location=42.3677994,-71.0708
078×tamp=1412649030&key=<your API key>
1.3 解析JSON
上面我们了解了不同类型的API(Twitter,Google)以及如何使用它们返回的JSON数据。这部分我们来看看如何解析JSON。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import json
from urllib.request import urlopen
def getCountry(ipAddress):
JSONFileHandler = urlopen("http://freegeoip.net/json/"+ipAddress) #获取JSONFile句柄
JSONFileString = JSONFileHandler.read().decode('utf-8') #用UTF-8读取成String
responseJSON = json.loads(JSONFileString) #json模块loads该String
return responseJSON.get("country_code") #获取其"country_code"对应的内容。
print(getCountry("168.70.77.50"))
#Output:
#HK
jsonString = '{"arrayOfNums":[{"number":0},{"number":1},{"number":2}],"arrayOfFruits":[{"fruit": "apple"}, {"fruit": "banana"},{"fruit": "pear"}]}'
jsonObj = json.loads(jsonString)
print(jsonObj.get("arrayOfNums"))
print(jsonObj.get("arrayOfNums")[1])
print(jsonObj.get("arrayOfNums")[1].get("number") + jsonObj.get("arrayOfNums")[2].get("number"))
print(jsonObj.get("arrayOfFruits")[2].get("fruit"))
# #Output:
# [{'number': 0}, {'number': 1}, {'number': 2}]
# {'number': 1}
# 3
# pear
json是Python Core Library中的一个库,不像其他语言将JSON文件转换成JSON object或者JSON node,Python用更灵活的方式将JSON objects转成dictionaries, JSON arrays转成lists, JSON strings转成strings等等。

2 APIs + BeautifulSoup
如果单一使用某个API,相当于使用一个已经发布的database,这并不十分有趣。如果将多个数据库combine,并且用一个崭新的视角(例如图形API)去解读它,那就更加吸引人了。比如在wikipedia的修改历史中,会记录修改过该页面的用户名或者IP地址(没有logo in的话);在这基础上,我们可以用freegeoip.net的API获得其物理地点;然后运用Google的Geochart library将其总结显示在地图上。这样通过整合多个不同database的API和展示数据的API,我们获得的数据就更加有意思了。
请看下面代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import json
import re
import datetime
import random
def getArticalTags(inputUrl):
url = "https://en.wikipedia.org" + inputUrl
htmlHandler = urlopen(url)
bsObject = BeautifulSoup(htmlHandler.read(), "html.parser")
return bsObject.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(\/wiki)((.(?!:))*)$"))
def getHistoryIPs(articalUrl):
# articalUrl="/wiki/Six_Degrees_of_Kevin_Bacon"
# revision history page pattern
# https://en.wikipedia.org/w/index.php?title=Kevin_Bacon&action=history
# https://en.wikipedia.org/w/index.php?title=Six_Degrees_of_Kevin_Bacon&action=history
title = articalUrl.replace("/wiki/","")
print("revision history of ",title," -------------------------")
revisionPageUrl = "https://en.wikipedia.org/w/index.php?title="+title+"&action=history"
htmlHandler = urlopen(revisionPageUrl)
bsObject = BeautifulSoup(htmlHandler.read(), "html.parser")
IPs= set()
for IPTag in bsObject.find("ul",{"id":"pagehistory"}).findAll("a",{"class":"mw-anonuserlink"}):
if IPTag.string not in IPs:
IPs.add(IPTag.string)
return IPs
def getIPCountry(IP):
JSONFileHandler = urlopen("http://freegeoip.net/json/" + IP)
JSONFileString = JSONFileHandler.read().decode('utf-8')
JSONObject = json.loads(JSONFileString)
IPCountry = JSONObject.get('country_name')
return IPCountry
def start(startPage):
articalTags = getArticalTags(startPage)
for articalTag in articalTags:
articalLink = articalTag.attrs["href"]
for IP in getHistoryIPs(articalLink):
print(IP, " from: ",getIPCountry(IP))
while(len(articalTags)>0):
i = random.randint[0,random.randint(len(articalTags)-1)]
randomArticalTag = articalTags[i]
start(randomArticalTag)
start("/wiki/Kevin_Bacon")
#Output:
# revision history of Kevin_Bacon_(disambiguation) -------------------------
# revision history of San_Diego_Comic-Con_International -------------------------
# 70.67.239.79 from: Canada
# 220.221.249.249 from: Japan
# 2602:306:b883:4f0:198d:191a:4f08:5b16 from: United States
# 2600:8801:9604:3900:7273:cbff:fe5c:336d from: United States
# 96.250.2.62 from: United States
# 134.223.230.151 from: United States
# 126.229.33.149 from: Japan
# 1.79.84.210 from: Japan
# 126.204.160.80 from: Japan
# 91.122.178.55 from: Russia
# 176.182.35.113 from: France
# revision history of Philadelphia -------------------------
该代码先提取某一页面的articalTags,然后获取每一个ariticalTag的history url,打开并找出其中的IP修改条目,然后将IP通过freegeoip.net换成国家,最后再随机访问任何一个ariticalTag并循环。
它的有意思的地方在于结合了BeautifulSoup和freegeoip.net的API,完成我们自己想要做的事情。
3. 总结
本文介绍了API:
-
和网址的不同在于返回XML或者JSON,而不是HTML;4种基于HTTP的通讯方式,即增(POST)删(DELETE)改(UPDATE)查(PUT);授权(Authentication)的意义;API call的格式;
-
3个API实例,Spotify,Twitter,和Google;
-
如何用Python core libary的json module 解析JSON;
以及如何将BeautifulSoup和API结合起来,挖取我们想要的数据。
本文最后总结成下图。

