目录
上篇文章我们已经介绍过BeautifulSoupAdvanced HTML Parsing的用法。本文我们用几个对真实网站抓取的例子来应用一下BeautifulSoup。这些例子根据涉及的域名数可以分为单域名和多域名,根据抓取的数量又可以分为随机抓取和完全抓取。
1 Singe-Domain
1.1 Random Walk
你应该听过六度分隔理论。
六度分隔理论(Six Degree of Separation):世界上任何两个人都可以通过最多六个人(包括他们自己)来联系到。
这在Wikipedia上可以等同于六度维基理论。
六度维基理论(Six Degree of Wikipedia):Wikipedia上任何两篇aritical的subject都可以通过最多六篇artical(包括他们自己)来linked到。
我们将要用BeautifulSoup尝试完成这个Project。本文将首先完成其中的第一部分:给定一个Wikipedial的artical,如何在它包含的artical里随机访问,直到某篇artical不包含其他artical为止。
该任务可以分解为下面几个步骤:
- 研究artical的网址的pattern。
- 通过BeautifulSoup来获取artical里的artical链接,随机访问其中一个artical,直到某个artical包含的artical为0为止。
1.1.1 Pattern Determination
-
所有artical的链接均出现在正文中,也就是<div id="bodyContent" ></div>中。
-
artical的网址举两个例子,很容易看出他们的共性。
/wiki/A_Few_Good_Men
/wiki/Kevin_Bacon
而边栏和底栏的链接如下:
/wiki/Special:Random
/wiki/Special:WhatLinksHere/Kevin_Bacon
//wikimediafoundation.org/wiki/Privacy_policy
因此我们需要的pattern也就清楚了,以/wiki开头,后面可以跟除了:之外的任意word。因此可以写成正则表达式
"^(\/wiki)((.(?!:))*)$",^(\/wiki)表示以/wiki开头,((.(?!:))*)$表示以((.(?!:))*)结尾,其中((.(?!:))*)表示≥0个(.(?!:))。(.(?!:))表示任意字符除了:。(?!:)在main expression即.后面附加一个不包括的条件。
1.1.2 Random Access to Webpage
我们先上代码,再分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
random.seed(datetime.datetime.now())
def getArticalTags(inputUrl):
url = "https://en.wikipedia.org" + inputUrl
htmlHandler = urlopen(url)
bsObject = BeautifulSoup(htmlHandler.read(), "html.parser")
return bsObject.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(\/wiki)((.(?!:))*)$"))
articleTagList = getArticalTags("/wiki/Kevin_Bacon")
while(len(articleTagList) > 0):
i = random.randint(0,len(articleTagList)-1)
articleUrl = articleTagList[i].attrs["href"]
print(articleUrl)
articleTagList=getArticalTags(articleUrl)
#Output:
#/wiki/Murder_in_the_First_(film)
# /wiki/Henri_Young
# /wiki/Henry_Young_(disambiguation)
# /wiki/Henry_Young_(major)
# /wiki/Union_Army
# /wiki/Department_of_the_Monongahela
# /wiki/Belmont_County,_Ohio
我们来逐步分析这块代码。随机数可以通过两行代码实现。
1
2
random.seed(datetime.datetime.now())
i = random.randint(0,len(articleTagList)-1)
我们先来看datetime.datetime.now()。第一个datetime是module,第二个是类(本来应该头字母大写,但是古老的python程序员当时并没有开始遵循类头字母大写的原则),now()是类方法,该类方法产生一个datetime的实例,并返回当前时间相对于1970年1月1日的秒数。
再来看random.seed()方法,文档中描述该方法”Create one instance of Random, seeded from current time(seed函数的参数必须是可hashable object), and export its methods as module-level functions.”。因为该实例的实例方法上升至module级别,所以后面可以用random.randint(0,len(articleTagList)-1)来产生随机数。Random实例其实是一个伪随机数产生器,给定相同的seed作为起始状态(initial internal state),每次产生的随机数的序列是一样的。这里我们用时钟来表示seed,因此每次产生的序列是不一样的。
剩下的代码就比较容易理解了。
完成随机跳转之后,我们还需要存储和分析数据来完成六度维基理论。这部分我们将在第5篇笔记中继续介绍。
1.2 Total Walk
在上节中,我们从一个网站的某个page来随机访问该网站的其他page。如果我们需要系统地获得某网站的全部网页,我们该怎么办呢?
也许有人会问,抓取某网站的全部网页有什么用呢。比如可以给客户生成网站地图,在客户你不给内部网站访问权限的前提下;还可以收集信息,比如在几个你认为最重要的网站中提取信息,比如从几个音乐网站中收集歌手的信息等。
通常的做法是从一个顶级的网页开始(比如首页),然后搜索所有该网站的内部网页,然后再在每一个内部网页进行循环操作,如此循环。这种情况下,网页数量会爆炸性增长,比如有5层深度的网站,每个网页有10个内部网页,那么总共将会有100000个网页(当然需要去掉大部分重复网页)。通常来说100000个网页是网站的上限了,大部分网站的网页数都不会超过100000。
所以为了避免重复抓取统一网页两次以上,已经被抓取的网页需要已统一的格式存储起来。只有新的内部网页才会被添加进来,进行内部网页抓取。
1.2.1 Sitemap
请看下面代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
pages = set()
def getInternalLinks(inputUrl):
url = "http://www.eee.hku.hk/~chchoy/" + inputUrl
htmlHandler = urlopen(url)
bsObject = BeautifulSoup(htmlHandler.read(), "html.parser")
try:
for link in bsObject.findAll("a",href=re.compile("^([^http])[^#@]*$")):
url = link.attrs['href']
if url is not None:
if url not in pages:
print(url)
pages.add(url)
getInternalLinks(url)
except HTTPError as e:
print(e)
getInternalLinks("")
print("finished")
print("totla number of internal pages: ", len(pages))
# Output: 4个页面
# index.html
# research.html
# facilities.html
# vacancies.html
# finished
# totla number of internal pages: 4
1.2.2 Site Data
如果只能生成网站地图,显得不是那么有趣。这里我们在上面的基础上,收集wiki每个内部网页的title和第一段以及edit links3个信息。请见如下代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
content = dict()
def getInternalLinks(inputUrl):
url = "https://en.wikipedia.org" + inputUrl
htmlHandler = urlopen(url)
bsObject = BeautifulSoup(htmlHandler.read(), "html.parser")
try:
title = bsObject.find("h1").string
para = bsObject.find(id="mw-content-text").findAll("p")[0]
editLinkUrl = bsObject.find(id="ca-edit").find("span").find("a").attrs['href']
print('--------------------------------')
print("title : ",title)
print("paragraph: ",para)
print("editLink : ",editLinkUrl)
print('--------------------------------')
content[title] = (para, editLinkUrl)
except AttributeError:
print("this site missing something!")
for link in bsObject.findAll("a",href=re.compile("^(\/wiki)((.(?!:))*)$")):
url = link.attrs['href']
if url is not None:
if url not in pages:
print(url)
pages.add(url)
getInternalLinks(url)
getInternalLinks("")
Regular Expression应该用什么pattern去匹配目标tag是这段代码的核心。关于获取数据的存储我们将在第5篇笔记中介绍。
1.2.3 External and Internal Link
请先看Multi-Domain Random Walk再回过头来看下面这段代码。
上述代码可以重构用来收集Single Domain下的所有外部和内部url。如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
...
def validateUrl(address):
validateAddress = address
if address.startswith("//",0,2):
validateAddress = "https:" + address
elif address.startswith("/",0,2):
validateAddress = "https://www.oreilly.com" + address
return validateAddress
allExtLinks = set()
allIntLinks = set()
def getAllExternalAndInternalLink(siteUrl):
try:
request = Request(siteUrl, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(request)
bsObj = BeautifulSoup(html,"html.parser")
internalLinks = getInternalLinks(bsObj,splitAddress(siteUrl)[0])
externalLinks = getExternalLinks(bsObj,splitAddress(siteUrl)[0])
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.add(link)
print(link)
for link in internalLinks:
if link not in allIntLinks:
allIntLinks.add(link)
print("About to get link: " +validateUrl(link))
getAllExternalAndInternalLink(validateUrl(link))
except HTTPError as e:
print(e)
print("https://www.flinhong.com/, external link number: ",len(allExtLinks))
print("https://www.flinhong.com/, internal link number: ",len(allIntLinks))
#Output:
# ...
# https://www.flinhong.com/, external link number: 103
# https://www.flinhong.com/, internal link number: 68
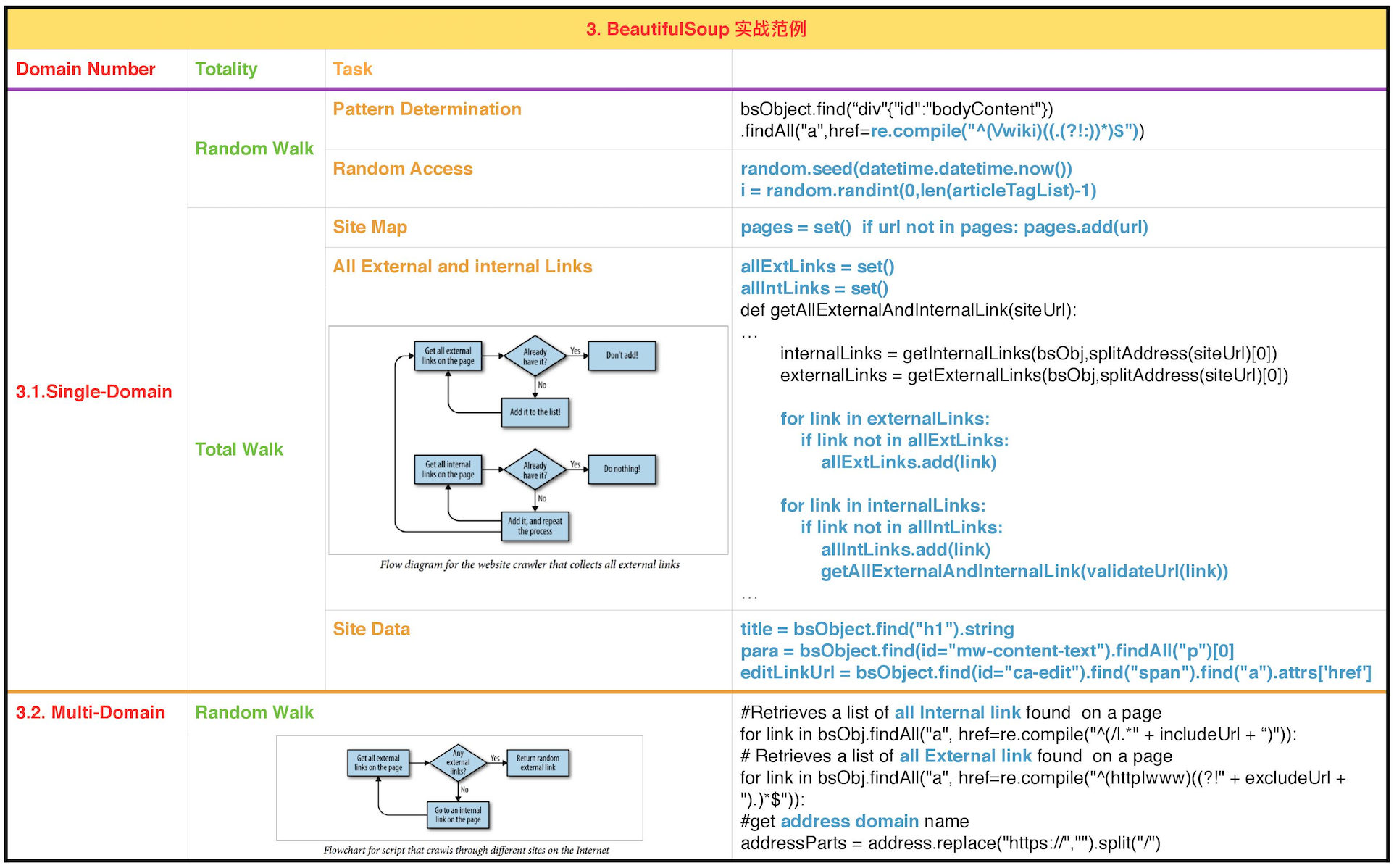
程序流程图如下。
2 Multi-Domain
如果让你建立google的搜索引擎,你该如何入手呢:
- 购买数据仓库放在世界各地;
- 写一个网络爬虫软件。
事实上1994年google刚建立时,当时斯坦福的两位研究生,拉里佩奇和谢尔盖布林,就是用一台老旧的服务器和一个Python的web crawler起步的!
严格来说,你并不需要很大的数据仓库,web crawler才是当代网络技术的核心。任何垮域名的数据收集和分析,关键在于如何建立eb crawler来过滤和存储数据。
2.1 Random Walk
现在我们来做更富有挑战性的任务。不像之前的只在单一域名上进行随机或者全部访问,我们来写一个跨域名随机访问的web crawler。
先上代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
#Retrieves a list of all Internal link found on a page
def getInternalLinks(bsObj,includeUrl):
internalLinks = []
#Finds all links that begin with a "/",.
#| alternation in Regex has lowest priority,
#the engine will match everything to the left of the bar, or the right of the bar
#也就是以/开头,或者以includeUrl开头
for link in bsObj.findAll("a", href=re.compile("^(/|.*" + includeUrl + ")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
internalLinks.append(link.attrs['href'])
return internalLinks
# Retrieves a list of all External link found on a page
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
# Finds all links that start with "http" or "www"
# (((非excludeUrl)后面跟任何word)0或者1次)结尾的
for link in bsObj.findAll("a", href=re.compile("^(http|www)((?!" + excludeUrl + ").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def splitAddress(address):
if "https://" in address:
addressParts = address.replace("https://","").split("/")
else:
addressParts = address.replace("http://", "").split("/")
return addressParts
def getRandomExternalLink(startingPage):
request = Request(startingPage, headers={'User-Agent': 'Mozilla/5.0'})
html = urlopen(request)
bsObj = BeautifulSoup(html,"html.parser")
externalLinks = getExternalLinks(bsObj,splitAddress(startingPage)[0])
if len(externalLinks) == 0:
internalLinks = getInternalLinks(bsObj,startingPage)
if len(internalLinks) == 1:
return getRandomExternalLink(internalLinks[0])
else:
return getRandomExternalLink(internalLinks[random.randint(0,len(internalLinks)-1)])
elif len(externalLinks) == 1:
return externalLinks[0]
else:
return externalLinks[random.randint(0,len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print("Random external link is: "+externalLink)
followExternalOnly(externalLink)
followExternalOnly("http://www.hku.hk")
#Output:
# Random external link is: http://fb.com/hkusa.dseteam
# Random external link is: https://www.facebook.com/hkusa.dseteam/?fref=nf
# Random external link is: http://l.facebook.com/l.php?u=http%3A%2F%2Fcablenews.i-cable.com%2Fwebapps%2Fsuddenfeed.php&h=UAQGaDwNJAQH7di2k2m3G19odhGe1MEunTAthBzkXaMsUAQ&enc=AZNOiAMBe59qZ0jRPRiqmNencoTWzwuMkWs-480Z9NNJ78urS-e7XaFgUcqdaKAfUJZDefYazVfXLpmeCIb4ou8CITstxOA29I8jzl6KVBi5FRfh3RcQe1cUoNfZX1VLpvxcZyAje0KDlCZJ1fJGiLtW9jDS4LmwrE9_aE4gZy9n1TplJ4IJdAj_lxqXZ5hOmPAsDHzxt-B6Smo8HNBOuRgR&s=1
# Random external link is: https://developers.facebook.com/?ref=pf
# Random external link is: https://www.facebook.com/seth.rosenberg
# Random external link is: https://id-id.facebook.com/seth.rosenberg
# ...
-
我们首先输入一个完整的网址
followExternalOnly("http://www.hku.hk"),其调用getRandomExternalLink(startingSite) -
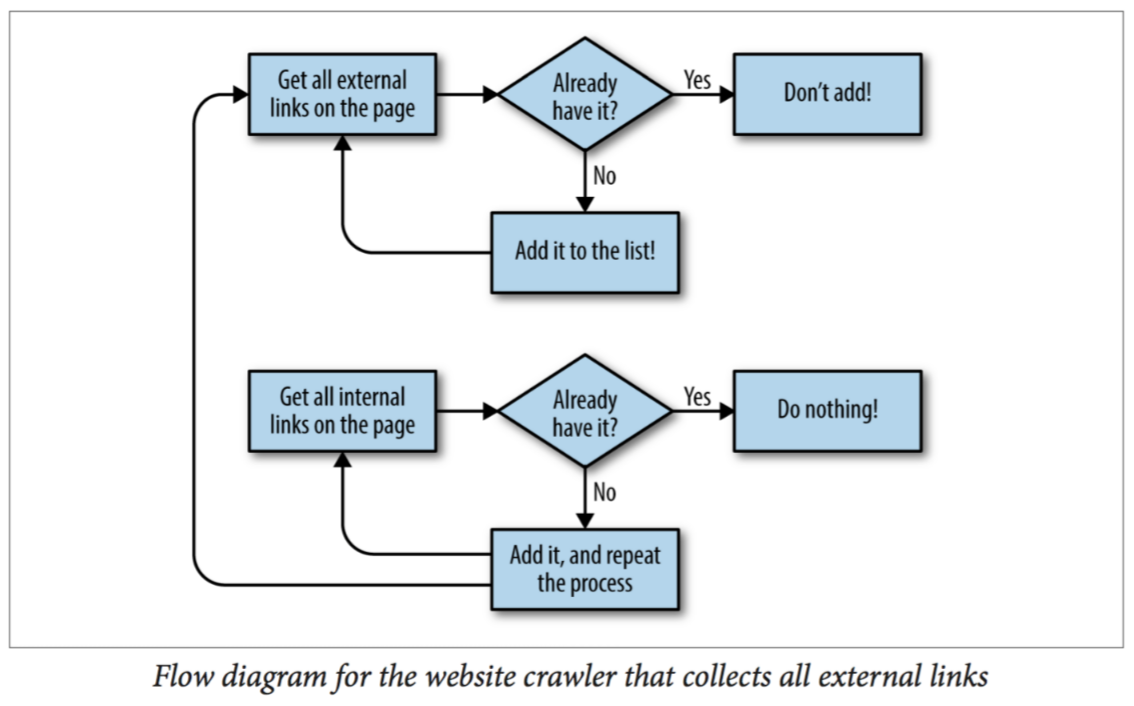
getRandomExternalLink(startingSite),该函数调用三个函数getExternalLinks(bsObj, excludeUrl),getInternalLinks(bsObj,includeUrl),splitAddress(address)。随机取外部url的List里的元素,如果外部url的List个数为0,则从内部url的List中随机取一个,进去再提取外部url,该逻辑图如下。 -
splitAddress(address):输入完整网址,返回其域名,例如输入http://www.hku.hk/sitemap.html,返回www.hku.hk。具体实现是将http://或者https://从startingSite中剔除,然后将剩下的网址按/分开,最后取第一个元素。 -
getExternalLinks(bsObj, excludeUrl):输入bsObj和域名,返回外部url的list。如何判断是外部呢,即http或者www开头,且不包括自己域名的url,re.compile("^(http|www)((?!" + excludeUrl + ").)*$"))。 -
getInternalLinks(bsObj,includeUrl):输入bsObj和includeUrl,返回内部url的list。如何半段是内部呢,url以\开头或者以自己域名开头,re.compile("^(/|.*" + includeUrl + ")"))
3 Scrapy介绍
写Web Scraping有几个重要的pattern,例如:
-
找到某page所有的link;
-
评估内部和外部链接的区别;
-
前往新页面。
当你从零开始写Web Scraping的时候,这些pattern非常有用。但我们还有另外一个选择,将这些细节交给某些框架处理,而我们只需要focus在主要业务逻辑上。Scrapy就是这样一个强大的Python Web Scraping的库。
Scrapy:a web crawling Python framework to extract data w/o APIs. 可以说Scrapy是BeautifulSoup(只是解析HTML和XML)更高一级的框架。
关于Scrapy的具体介绍,这里按下暂时不表。以后我们将在另一篇文章中详解。
4 总结
本文从Single-Domain(Randm Walk && Total Walk(External Links+Internal Links, Site Map, Site Data))及Multi-Domain(Random Walk)这5个基础的例子,从真实的网站中带我们领略了BeautifulSoup的功能,也给我们日后的Web Scraping设立了5个基本的任务范本。最后将本文内容总结成下图以供参考。