
目录
1. 函数式数据结构的典型:List
2. Sequence
2.1 List

2.1 基础
List在Scala里是immutable,它的实现是recursive的。
List是一个抽象接口Trait,它的子类个数Empty和NonEmpty已经确定下来,因此根据我们上文Pattern Matching和OOP decompostion的比较,接口方法的扩展在Trait里用Pattern Matching实现尤其方便。
- 构造器,所有List从以下两种方法构造出来:
- Nil,表示Empty的单例
- x::xs,表示NonEmpty的实例,等同于 new Cons(x,xs)
- head,tail,isEmpty
- head,NonEmpty的第一个元素,即(x::xs)中的x
- tail,NonEmpty的除了第一个元素外的元素,即(x::xs)中的xs
- isEmpty,NonEmpty是false,Empty是true
- pattern matching ,见上图3种情况,分别代表空,1个元素,和多于1个元素的pattern。
2.2 一阶函数
List一阶函数包括上图几种API,这里就不详细讲解了。 下面我们结合List的一阶函数和pattern matching,来实现下merge sort:
- 先分一半;
- 左右各做sort;
- sort完merge。
其实就是典型的分而治之的思想,我们先看下用Scala的List如何实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def msort1(x: List[Int]): List[Int] = {
val mid = x.length / 2
if (mid == 0) x
else {
def merge(xs: List[Int], ys: List[Int]): List[Int] = xs match {
case Nil => ys
case x::xs1 => ys match {
case Nil => xs
case y::ys1 =>
if (x < y) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
}
val (fst, snd) = x.splitAt(mid)
merge(msort1(fst), msort1(snd))
}
}
这里mergemethod的pattern matching稍显杂乱,我们想要表达的是xs或者ys为空或者不为空的情况,由于用了嵌套的pattern matching降低了程序的可读性。我们能否进一步提高呢?
2.2.1 tuple(元组)
答案是可以的。我们得用元组。
tuple(元组):不同与List或者数组(将同样类型的元素组合成一个),元组是将多个不同类型的变量组合成一个。
因此我们可以将嵌套Pattern Matching简化为一个tuple(xs,ys)的Pattern Matching。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def msort2(x:List[Int]):List[Int] = {
val mid = x.length/2
if (mid == 0) x
else{
def merge(x:List[Int],y:List[Int]):List[Int] = (x, y) match {
case (Nil,y) =>y
case (x,Nil) =>x
case (x1::xs1, y1::ys1) =>{
if(x1 < y1) x1 :: merge(xs1,y)
else y1 :: merge(x, ys1)
}
}
val (fst,snd) = x.splitAt(mid)
merge(msort2(fst),msort2(snd))
}
}
元组的语法如下:
1
2
val pair = ("answer",42)
val (label, value) = pair //label = "answer", value = 42
由上面的例子可以看到元组的使用,可以将多参数表示成单参数(子参数平行),使得代码的逻辑和可读性大大增强。
2.2.2 隐式参数
上面的例子只是对于List[Int]来进行排序,能否用泛型将type参数化呢?答案是可以的。关键要在merge函数里实现x < y的定义。因此我们得输入另一个lt:(T,T)=>Boolean的参数给msort。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def msort3[T](x:List[T])(lt:(T,T)=>Boolean):List[T] = {
val mid = x.length/2
if (mid == 0) x
else{
def merge(x:List[T],y:List[T]):List[T] = (x, y) match {
case (Nil,y) =>y
case (x,Nil) =>x
case (x1::xs1, y1::ys1) =>{
if(lt(x1,y1)) x1 :: merge(xs1,y)
else y1 :: merge(x, ys1)
}
}
val (fst,snd) = x.splitAt(mid)
merge(msort3(fst)(lt),msort3(snd)(lt))
}
}
val numbers = List(-4,2,6,-10,9,8,5)
msort3(numbers)((x,y)=>x<y)
val fruits = List("apple", "pear", "watermelon","banana")
msort3(fruits)((x:String,y:String)=>x.compareTo(y)<0)
在调用msort3的时候,我们得显示提供这个比较参数。
那么对于基础类型的比较,scala有没有已经实现了的方法,比如Java里的Comparable接口,从而可以简化我们的比较函数呢,答案也是可以的。我们得用到scala.math.Orderinng类。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def msort4[T](x: List[T])(ord:Ordering[T]): List[T] = {
val mid = x.length / 2
if (mid == 0) x
else {
def merge(x: List[T], y: List[T]): List[T] = (x, y) match {
case (Nil, y) => y
case (x, Nil) => x
case (x1 :: xs1, y1 :: ys1) => {
if (ord.lt(x1, y1)) x1 :: merge(xs1, y) //用Ordring的lt方法。
else y1 :: merge(x, ys1)
}
}
val (fst, snd) = x.splitAt(mid)
merge(msort4(fst)(ord), msort4(snd)(ord))
}
}
val numbers = List(-4,2,6,-10,9,8,5)
msort(numbers(Ordering.Int)
val fruits = List("apple", "pear", "watermelon","banana")
msort(fruits)(Ordering.String)
最后我们可以用implicit ord: Ordering[T]在msort定义和时作为输入参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def msort[T](x: List[T])(implicit ord: Ordering[T]): List[T] = {
val mid = x.length / 2
if (mid == 0) x
else {
def merge(x: List[T], y: List[T]): List[T] = (x, y) match {
case (Nil, y) => y
case (x, Nil) => x
case (x1 :: xs1, y1 :: ys1) => {
if (ord.lt(x1, y1)) x1 :: merge(xs1, y)
else y1 :: merge(x, ys1)
}
}
val (fst, snd) = x.splitAt(mid)
merge(msort(fst), msort(snd)) //ord 对merge可见,因此可以省略
}
}
val numbers = List(-4,2,6,-10,9,8,5)
msort(numbers) //调用时,也不需要提供Ordering实例,Scala会自己判断
val fruits = List("apple", "pear", "watermelon","banana")
msort(fruits) //调用时,也不需要提供Ordering实例,Scala会自己判断
2.3 高阶函数
好了,铺垫了前面4篇文章和本文前面的List基础和一阶函数。我们终于来到了List的高阶函数了,这相当于FP的第一道主食,前面都是开胃小菜,等待了那么久,第一道硬菜终于上桌了。我们来好好享受函数式数据结构List高阶函数带来的解决什么问题而不是怎样解决问题这么一个函数式编程广为赞誉的特性。
函数式编程高阶函数一般解决以下三个问题:
- filter(筛选),retrieving a list of all elements satifying a criterion;
- map(映射),transforming each elements in a list;
- reduce(化约)和fold(折叠),combining elements of a list using an operator。
2.3.1 filter(筛选)
1
2
3
4
5
6
7
def filter[T](xs:List[T])(p:T=>Boolean):List[T] = xs match {
case Nil => Nil
case x::xs1 => if (p(x)) x::filter(xs1)(p) else filter(xs1)(p)
}
val numbers = List(-4,2,6,-10,9,8,5) //List(-4, 2, 6, -10, 9, 8, 5)
val fNumers = filter(numbers)(x=>x>0) // List(2, 6, 9, 8, 5)
我们定义了一个高阶函数(Currying)来实现多参数的输入(xs和p)。若xs是空则返回空;若不是空,则判断是否通过条件,通过则留下,进一步filter剩下的,否则直接filter剩下的。
那么我们使用filter的时候,只需要在提供一个List实例之外,提供一个p:(T)=>Boolean(也就是解决每个元素通过的规则的问题),就可以获得最终符合条件的元素组成的List。
2.3.2 map(映射)
1
2
3
4
5
6
7
def map[T,U](xs:List[T])(p:T=>U):List[U] = xs match {
case Nil => Nil
case x::xs1 => p(x)::map(xs1)(p)
}
val numbers = List(-4,2,6,-10,9,8,5) //List(-4, 2, 6, -10, 9, 8, 5)
val mapNumbers = map(numbers)((x:Int) => x * x) //List(16, 4, 36, 100, 81, 64, 25)
同理,我们有了一个一一对应的map函数,只需要提供一个List实例和p:(U)=>T(解决每个元素映射的规则的问题),就可以获得一个新的映射后的List。
2.3.3 reduce(化约) 和 fold(折叠)
reduce(化约)和fold(折叠)是combining elements of a list using an operator。分别分为reduceLeft(左化约),foldLeft(左折叠);以及reduceRight(右化约),foldRight(右折叠)。
1
2
3
4
5
6
7
8
9
10
11
12
def foldLeft[T,U](xs: List[T])(z:U)(op:(T,U)=>U):U = xs match {
case Nil => z
case x::xs1 => foldLeft(xs1)(op(x,z))(op)
}
def reduceLeft[T](xs:List[T])(op:(T,T)=>T):T = xs match {
case Nil =>throw new Error("Nil.reduceLeft")
case x::xs1 => foldLeft(xs1)(x)(op)
}
val rlNumber = reduceLeft(0::numbers)((x,y)=>x+y) //> rlNumber : Int = 16
val flNumber = foldLeft(numbers)(0)((x,y)=>x+y) //> flNumber : Int = 16
reduceLeft是folderLeft的特殊形式。
reduceRight,folderRight类似于reduceLeft,folderLeft,只不过不是从List头开始,而是从List尾开始
1
2
3
4
5
6
7
8
9
10
11
12
def foldRight[T, U](xs: List[T])(z: U)(op: (T, U) => U): U = xs match {
case Nil => z
case x :: xs1 => op(x,foldRight(xs1)(z)(op))
}
def reduceRight[T](xs: List[T])(op: (T, T) => T): T = xs match {
case Nil => throw new Error("Nil.reduceLeft")
case x :: xs1 => foldRight(xs1)(x)(op)
}
val rrNumber1 = reduceRight(0::numbers)((x,y)=>x+y) //> rlNumber1 : Int = 16
val frNumber1 = foldRight(numbers)(0)((x,y)=>x+y) //> rlNumber1 : Int = 16
因此一个List元素求和和元素求积的函数可以方便表示成下列代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
//((x:Int,y:Int)=>x+y) 可以简写成_+_,第一个"_"表示第一个输入参数,第二个"_"表示第二个输入参数
def sum0(xs:List[Int]):Int = reduceLeft(0::xs)(_+_)
def sum1(xs:List[Int]):Int = foldLeft(xs)(0)(_+_)
sum0(numbers) //> res0: Int = 16
sum1(numbers) //> res1: Int = 16
def prod0(xs:List[Int]):Int = reduceLeft(1::xs)(_*_)
def prod1(xs:List[Int]):Int = foldLeft(xs)(1)(_*_)
prod0(numbers) //> res2: Int = 172800
prod1(numbers) //> res3: Int = 172800
下面是一个练习,如何实现一个pack[T](xs:List[T]):List[List[T]],当xs = List('a','a','a','b','d','d','d','d','a')时,输出xs = List(List('a','a','a'),List('b',1),List('d','d','d','d'),List('a'))。
1
2
3
4
5
6
7
def pack[T](xs:List[T]):List[List[T]] = xs match{
case Nil => Nil
case x::xs1 => {
val (fst,snd) = xs.span(y=>x==y)
fst::pack(snd)
}
}
进一步如何实现一个encode[T](xs:List[T]):List[(T,Int))],当xs = List('a','a','a','b','d','d','d','d','a')时,输出xs = List(List('a',3),List('b',1),List('d',4),List('a',1))。我们可以用Pattern Matching类似pack一样实现。但是可以用另外一种思路,就是对pack的输出进行map,相当于将xs进行pack后再进行map的链式transformation。链式transformation在函数式编程中尤其有用,可以将十几行的命令式编程的代码用一条代码解决,简洁紧凑。
1
def pack[T](xs:List[T]):List[List[T]] = pack(xs).map(ys=>(ys.head,ys.length))
最后用一张图对List进行总结:
2.2 Vector
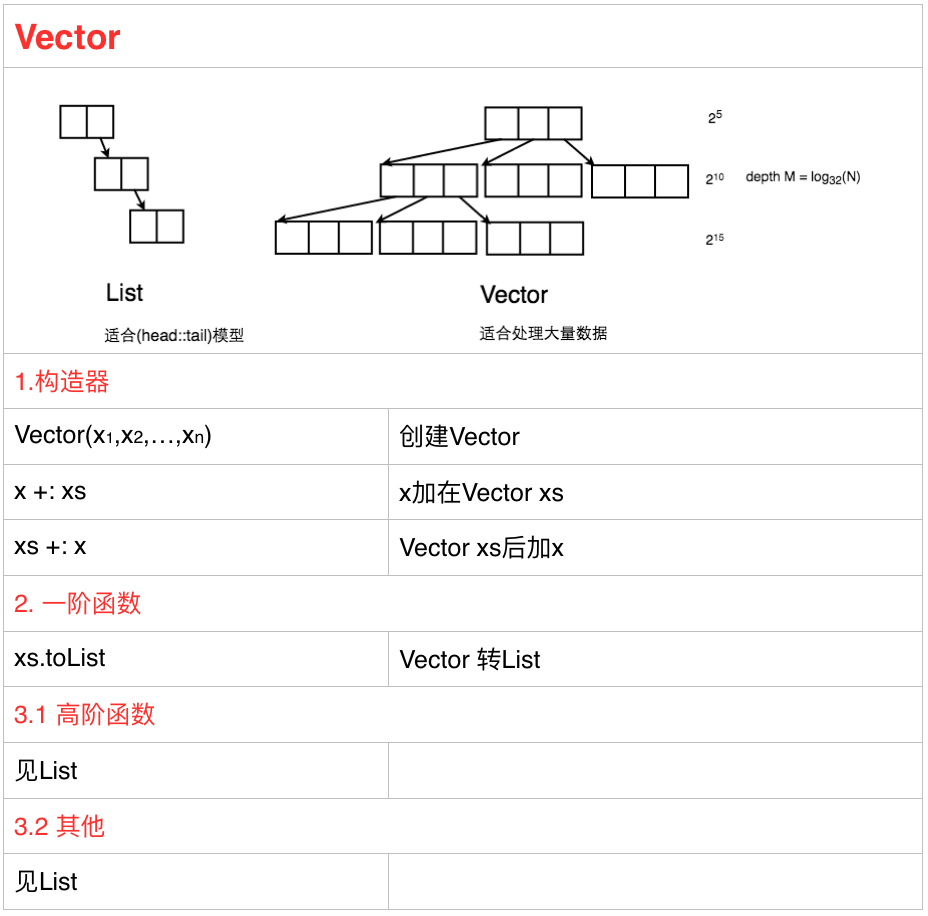
Vector的API大部分和List一样,主要区别是Vector适合操作大量数据而List适合那些操作(head::tail)模型的操作。对于32位为单位的Vector,它的深度M = log32(N)~O(lgN),因此对于大量数据的读取,优于List的O(N)(List的元素不会保证在一个page上)。
Vector可以用toList转换成List,也可以用x+:xs或者xs:+x分别在Vectorxs头尾增加x。
用Vector实现向量的点积运算。
1
def scalarProduct(xs:Vector[Double],ys:Vector[Double]):Double = (xs.zip(ys)).map(xy=>xy._1*xy._2).sum
2.3 Range
Range表示一个有[lowerBound,UpperBound]和nonZero Step的整数序列。
下面实现一个简单的栗子。给定两个整数N,M,给出所有的组合(i,j),使得1<=i<= N且1<=j<= M;
1
def combine(N:Int)(M:Int)= (1 to N).map(x => (1 to M).map(y => (x,y)))
2.4 Array && String
Array和String在Scala里也是Sequence的子类,实现是Java的Array和String。但是对它们进行类似List的高阶函数的时候,它们会被自动转换成Sequence。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
val numbs = Array(1, 2, 6, 3, 9, 7) //> numbs : Array[Int] = Array(1, 2, 6, 3, 9, 7)
val mNumbers = numbs.map(_ * 2) //> mNumbers : Array[Int] = Array(2, 4, 12, 6, 18, 14)
val strings = "Hello, World" //> strings : String = Hello, World
val fStrings = strings.filter(_.isUpper) //> fStrings : String = HW
strings.exists(_.isUpper) //> res0: Boolean = true
strings.forall(_.isUpper) //> res1: Boolean = false
val zip = strings.zip(numbs) //> zip : scala.collection.immutable.IndexedSeq[(Char, Int)] = Vector((H,1), (e
//| ,2), (l,6), (l,3), (o,9), (,,7))
val unzip = zip.unzip //> unzip : (scala.collection.immutable.IndexedSeq[Char], scala.collection.immu
//| table.IndexedSeq[Int]) = (Vector(H, e, l, l, o, ,),Vector(1, 2, 6, 3, 9, 7))
//|
val flatMap = numbs.flatMap(x => List(x, x * 2))//> flatMap : Array[Int] = Array(1, 2, 2, 4, 6, 12, 3, 6, 9, 18, 7, 14)
numbs.sum //> res2: Int = 28
numbs.product //> res3: Int = 2268
numbs.max //> res4: Int = 9
numbs.min //> res5: Int = 1
3 Set
Set没有序列,也不存在重复的元素。
1
2
3
4
5
6
val fruit = Set("apple","banana","pearl","appp")//> fruit : scala.collection.immutable.Set[String] = Set(apple, banana, pearl,
//| appp)
val s = (1 to 6).toSet //> s : scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4)
fruit.filter(_.startsWith("app")) //> res0: scala.collection.immutable.Set[String] = Set(apple, appp)
s.map(_+2) //> res1: scala.collection.immutable.Set[Int] = Set(5, 6, 7, 3, 8, 4)
s.nonEmpty
4 Map
Map是一个key对应一个value,有以下四点需要注意:
Map可作为高阶函数映射的输入参数,因为它本质上是一个函数,给定输入,有固定输出值;Map对值的access有两种方式。capitalOfCountry(“US”)`返回可以是异常,当没有这个value的时候;而capitalOfCountry.get(“China”)返回可以是Option(None),也可以是Option(String),不会抛异常。关于可选值Option我们在下节中详细介绍。Map可以有默认值,使得capitalOfCountry("US")异常取消,返回一个固定值。实现用withDefaultValue();Collection可以通过groupBy转换成Map。groupBy[K,V](f: V=>K): Map[K,List[V]],其中K是新的Map的键值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//1. Map as input argument for map
val romanNumerals = Map("I"->1,"V"->5, "X"->10) //Map(I -> 1, V-> 5, X -> 10)
val romans = List("I","V").map(romanNumerals) //List[Int] = List(1, 5)
//2. Map's two way to access elements
val capitalOfCountry = Map("US"->"Washington","Switzerland"->"Bern")
//Map(US -> Washington, Switzerland -> Bern)
capitalOfCountry("US") //String = Washington
capitalOfCountry.get("China") //Option[String] = None
capitalOfCountry.get("US") //Option[String] = Some(Washington)
//3. Map add default value
val capitalOfCountry2 = capitalOfCountry.withDefaultValue("not found")
//Map(US -> Washington, Switzerland -> Bern)
capitalOfCountry2("China") //String = not found
//4. convert List to Map by groupBy
val fruits = List("apple","pear","pineapple","orange")
//List(apple, pear, pineapple, orange)
fruits.groupBy(x=>x.head) //Map(p -> List(pear,pineapple), a -> List(apple), o -> List(orange))
5 总结

