
目录
1. OOP
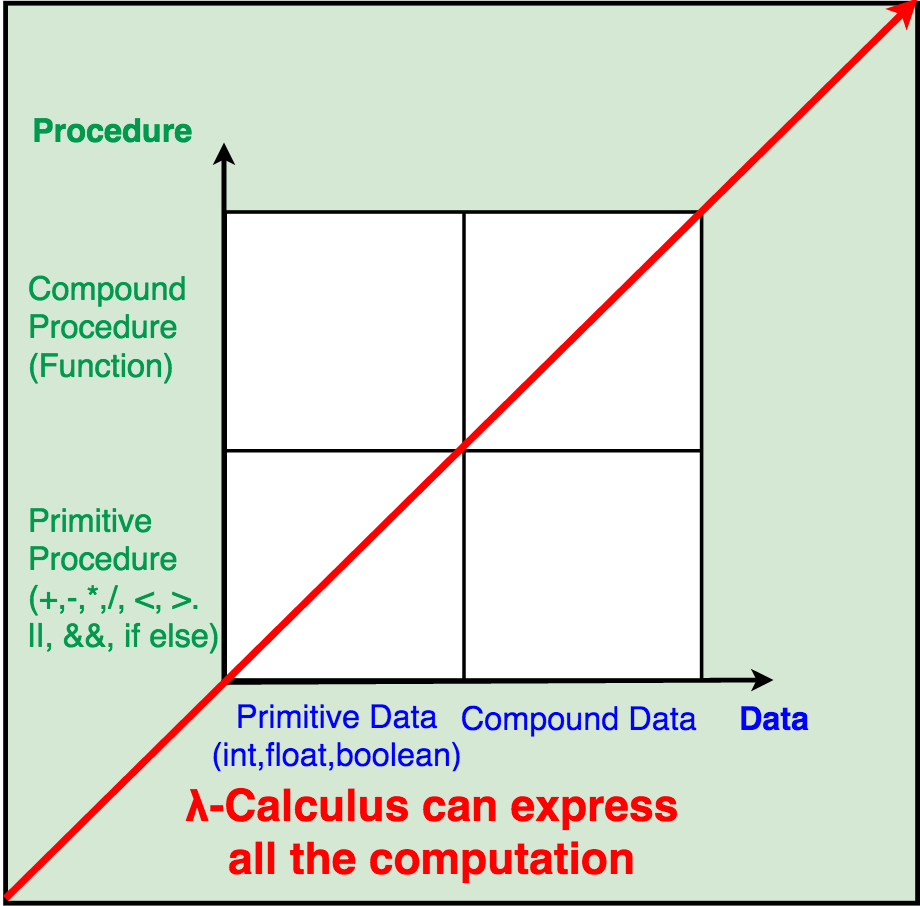
2. 万物皆类
2.1 Primitive Data is Class
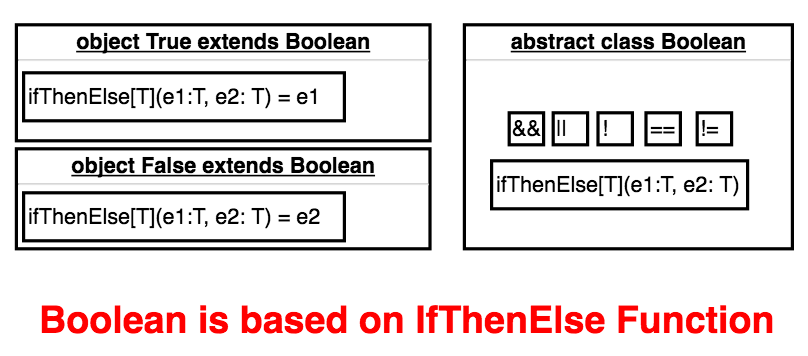
如果说让你定义一个布尔基础类Boolean,你会怎么做呢?Scala里的实现如下,先上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
package week4
object Main{
abstract class Boolean{
def ifThenElse[T](e1: => T, e2: => T): T
def && (b2: => Boolean): Boolean = ifThenElse(b2,False)
def || (b2: => Boolean): Boolean = ifThenElse(True,b2)
def unary_! : Boolean = ifThenElse(False,True)
def == (b2: Boolean): Boolean = ifThenElse(b2, b2.unary_!)
def != (b2: Boolean): Boolean = ifThenElse(b2.unary_!, b2)
}
object True extends Boolean{
def ifThenElse[T](e1: => T, e2: => T): T = e1
}
object False extends Boolean{
def ifThenElse[T](e1: => T, e2: => T): T = e2
}
def main(args: Array[String]) {
def p(b:Boolean) = b.ifThenElse(println("True"),println("False"))
p(True) //True
p(False) //False
p(True && False) //False
p(True && True) //True
p(False && True) //False
p(False && False) //False
p(True || False) //True
p(True || True) //True
p(False || True) //True
p(False || False) //False
p(!True) //False
p(!False) //True
p(True == False) //False
p(True == True) //True
p(False == False) //True
p(False == True) //Flase
p(True != False) //True
p(True != True) //False
p(False != False) //False
p(False != True) //True
}
}
课程里只是给了如上一个完成了的Boolean的实现,令人感叹于它的优雅。可是如果是让你重头开始自己设计Boolean,怎样才能获得这样的结果呢?对于编程学习者,我们渴求的不是Boolean的实现,而是Boolean实现的思路;正如物理学家渴求的不是相对论,而是发现相对论的那个头脑。我们来试着思考下:
- 首先,
Boolean有两个子类True和False,这是毋庸置疑的; - 这两个子类实现的最基本的功能应该就是单元操作,而不是多元操作;
- 那么我们先看看单元操作,有取反
!,和条件判断if (b:Boolean) e1 else e2; - 我们暂且将这个函数定义为
def ifThenElse[T](e1: => T, e2: => T): T,即假定Scala已经自动实现了上述将if (b:Boolean) e1 else e2转换成b.ifThenElse(e1,e2); - 那么两个子类
True和False对该函数的实现分别为返回e1和e2也就理所应当了; - 在这个基础上,我们尝试用
ifThenElse[T](e1: => T, e2: => T): T实现取反的单元操作和其他二元操作,结果证明是可行的。
我觉得上述思路应该是一个正常的思路,如果一开始就尝试用一个general的公式取实现Boolean所有的单元和多元操作,比较困难。我们留一个小问题,请同学自己实现Boolean的 < method.
最后Boolean的实现用以下这张图表示。
2.2 Compound Data is Class
这个同学们应该都很熟悉了,就是最常见的类的对data和function的封装(当function被封装在类里,我们称之为method,具体区别见2.4。我们重新改写λ-演算 Part III:抽象数据的有理数的例子,将Compound Data改写成类,只需将函数封装到数据里面即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
object Main {
class Rational(x: Int, y: Int) {
require(y != 0, "demoninator must be non-zero")
val numer = x / gcd(x, y)
val denomi = y / gcd(x, y)
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
// compared to the previous compound data example, here function are defined inside Rational
override def toString() = this.numer + "/" + this.denomi
def makeRationl(x: Int) = new Rational(x, 1)
def neg(r: Rational) = new Rational(-r.numer, r.denomi)
def add(r2: Rational): Rational = {
new Rational(this.numer * r2.denomi + this.denomi * r2.numer, this.denomi * r2.denomi)
}
def sub(r2: Rational): Rational = add(neg(r2))
def less(r2: Rational): Boolean = this.numer * r2.denomi - this.denomi * r2.numer < 0
def max(r2: Rational) = if (this.less(r2)) r2 else this
}
def main(args: Array[String]) {
val r1: Rational = new Rational(4, 5)
val r2: Rational = new Rational(3, 4)
val r3 = r1.add(r2)
println(r3)
val r4 = r1.sub(r2)
println(r4)
val r5 = r1.max(r2)
println(r5)
}
}
2.3 Primitive Procedure is Class
那么如何将诸如+,-,*,\的Primitive Procedure表示成类呢,其实我们在2.1已经看到了如何将。。——————————————
2.4 Compound Procedure is Class
Compound Procedure即函数,在scala里,函数如何才能使一个类呢?
function variable are class,and function value are object。
function value is from instantiation of function literals(anonymous functions)。
如果一个函数的类型是 A=>B,那么在scala里,这会转成scala.Function1[A,B],其中A和B是泛型,1表示输入参数是1个,Function1[A,B]表示1个输入类型A和1个输出类型B的函数类。那么这个类的定义是什么呢?是一个如下的接口,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
trait Function1[A,B]{
def apply(x:A):B
}
//变量f1是Int=>Int的函数,函数体是(x:Int)=>x*x;这个定义的完整版如下f2(f1,和f2等价)
val f1: Int=>Int = (x:Int)=>x*x
//变量f2,实例化一个Function1[A,B]的子类Function1[Int,Int],其中的apply method的实现就是f1中的函数体。
val f2 = new Function1[Int,Int]{
def apply(x:Int)=x*x
}
//f1调用
f1(3) //9
//f1会被转换成
f1.apply(3) //9
上面f2实例化一个Function1[A,B]的子类Function1[Int,Int],其中的apply method的实现就是f1中的函数体。
也许有人会问,apply 会再实例化一个函数类吗,如果会,不就陷入死循环了吗?
这里我们要着重讲解两个概念Function vs Method。
A function in Scala is a complete object,which contains methods, One of these methods is the apply method, which contains the code that implements the body of the function。 A method(an OOP concept) is defined within class and without class, there is no method。
在了解function和method的关系下,有几个method和function相互替代的地方需要注意:
- method 只能是def,function可以是val(即一个变量指向一个函数object)。
- method可以被隐式转换成function,如:
1 2 3 4 5 6 7
def m(x:Int) = x*x val f = m //error val f1 = m _ //return a new Function1[Int,Int]{def apply(x:Int)=x*x} val f2 = m(_) //the same as f1 val f3 = new Function1[Int,Int]{ //f1,f2 are actually converted as f3 def apply(x:Int)= m(x) }
- function通常比实现同样功能的method占用更多内存,但是function可以有OOP带来的其它好处,比如Scala默认实现了toString()。所以有些时候用function用内存换来的性能是值得的。
1 2 3
def m(x:Int) = x*x m.toString() //error f1.toString() //res5: String = <function1>>
- def evaluates every time it gets called while val evaluates only once。
1 2 3 4 5 6 7 8
def isDivisibleBy(k: Int): Int => Boolean = i => i % k == 0 def isEven1 = isDivisibleBy(2) isEven1(2)(5) isEven1(2)(5) // isDivisibleBy(k: Int): Int => Boolean is called every time val isEven2 = isDivisibleBy(2) isEven2(2)(5) isEven2(2)(5) // isDivisibleBy(k: Int): Int => Boolean is called only once during val isEven2's definition.
3. Scala中的类
既然Scala中万物皆类,我们来看下类需要特别注意的地方,包括语法和类等级(Class Hierachy)。
3.1 类的关键词
Scala里类的语法还有以下关键词。
- this,和Java里的this一样,在类里指自己这个实例。但是Scala里的this还可以是一个构造器。
1 2 3 4 5
class Rational(x: Int, y: Int) { //这是一个默认构造器 ... def this(x: Int) = this(x,1) //如果只输入一个参数x,那么自动生成分子为x,分母为1的Rational实例 ... }
- require,used to enforce a precondition on the caller of a function。
1 2 3 4
class Rational(x: Int, y: Int) { require(y != 0, "demoninator must be non-zero") //用来规定一个precondition,当对Rational构造器调用时。 ... }
- assert,used to check the code of the function itself。
assert和assert的区别在他们各自的定义里基本说清楚了,需要补充的是assert其实更多的是类的implementation的时候的先决条件,而assert更多的是一种对程序当前状态是否已达预期的一种判断。
1 2 3 4 5
class Rational(x: Int, y: Int) { ... assert(y != 0) // up to here,check whether y!=0 ... }
- trait,类似Java里的interface,但是比它强大,因为trait可以有method的具体实现和field(但是不能有value)。Swift的protocal和Scala的trait非常相似。
1 2 3 4 5 6
trait Movable{ ... val speed:Int; //field cannot have value def trace(x:Int) = x*x //method can have implementation,can be override ... }
3.2 多态和泛型
Polymorphism(多态),在OOP中有两种形式存在于类中:
- 类的subTyping,即当需要一个父类的时候,子类可以代替父类;
- 类的generic,即定义类和定义类中的method的时候,input argument type can be parameterized。
3.3 类等级
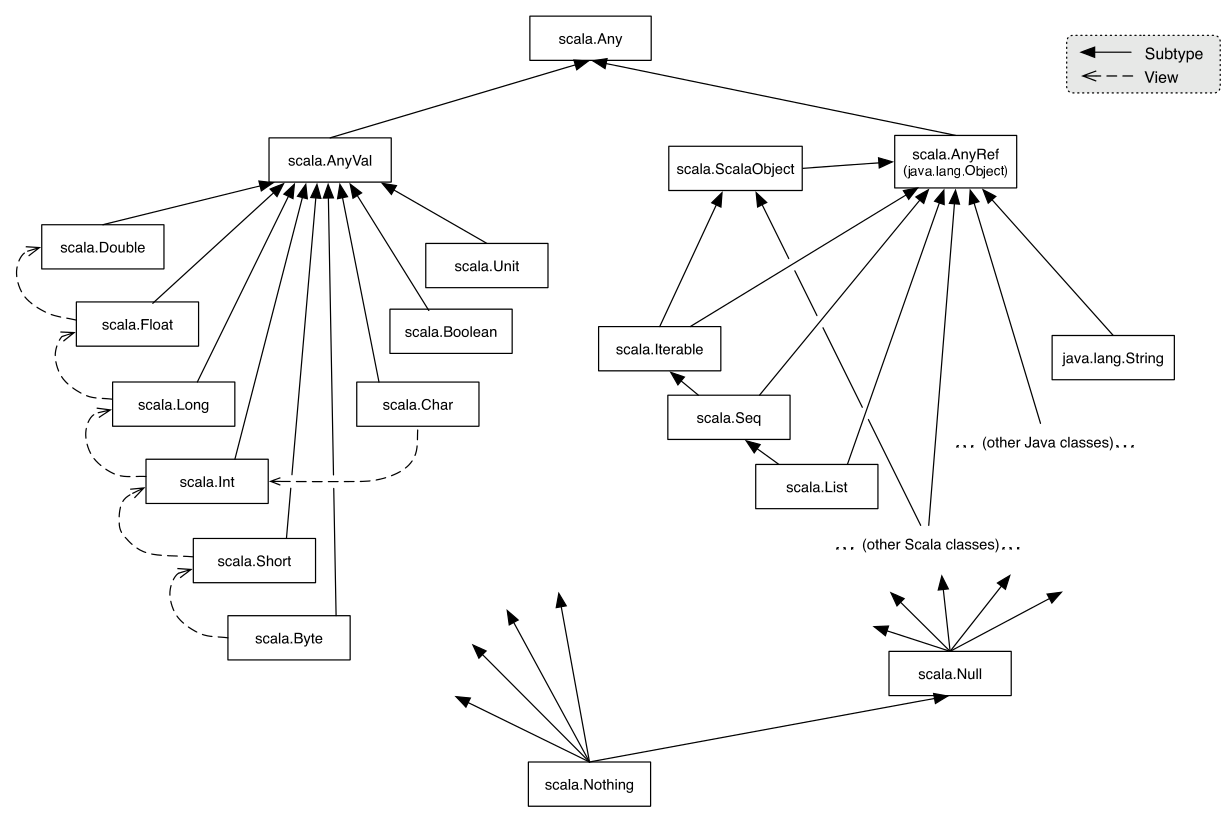
在Scala里,类等级(Class Hierachy)如上图所示:
-
所有类的祖先是
Any。Any又包括AnyVal和AnyRef,即分别是Primitive Data和Compound Data; -
AnyRef里的底部的子类是Null,AnyVal里的底部的子类是Nothing。同时Nothing又是Null的子类。 -
关于
AnyRef里的Iterable,Seq,List等接口我们暂且不表。
3.4 运行时和dynamic method dispatch
这里暂且不表,具体请先参见Objective-C的runtime系列。
4. 函数式特性的体现:Pattern Matching
pattern match是Scala为了避免为同一类添加一个新方法导致大量修改子类。由于OOP和λ-Calculus结合的函数式(递归)特性催生了这一pattern match模式。下面我们以一个算术表达式为例子(有Number,表示数字;Sum,有左Operand和右Operand),逐步理解pattern match的来历,优点及不足。
4.1 OOP Decomposition
Object-oriented decomposition: breaks a large system down into progressively smaller classes or objects that are responsible for some part of the problem domain。
我们将Number和Sum同时抽象成Expr接口。Expr接口里,我们分别实现了classification和accessor为了同时满足Number和Sum的操作(其实有冗余,Sum不需要numberValue,同时Number不需要leftOp,rightOp)。我们让Number和Sum同时实现Expr接口(即实现这5个method)。最后我们定义了一个eval(e: Expr): Int method 来实现最终的赋值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
trait Expr {
//classification
def isNumber: Boolean
def isSum: Boolean
//accessor
def numValue: Int
def leftOp:Expr
def rightOp:Expr
}
class Number(n:Int) extends Expr{ //the Number subclass
def isNumber: Boolean = true
def isSum: Boolean = false
def numValue: Int = n
def leftOp:Expr = throw new Error("Number.leftOp")
def rightOp:Expr = throw new Error("Number.rigthOp")
}
class Sum(left:Expr, right:Expr) extends Expr{
def isNumber: Boolean = false
def isSum: Boolean = true
def numValue: Int = throw new Error("Sum.numValue")
def leftOp:Expr = left
def rightOp:Expr = right
}
object ExprTest extends App{
def eval(e: Expr): Int = {
if (e.isNumber) e.numValue
else if (e.isSum) eval(e.leftOp) + eval(e.rightOp)
else throw new Error("Unknown expression" + e)
}
val x = new Sum(new Number(1), new Number(2))
println(x.toString())
}
上面的代码对于实现Number和Sum是没有问题的,但是它的扩展性不好,比如我们需要增加一个子类Prod用来计算乘积和一个子类Val来表示变量,我们需要如何改动呢:
- Expr的接口里需要再增加3个方法,
isProd,isVal,val。前两个是classification,第3个是accessor; Number和Sum需要实现这额外的3个方法。- 新增的
Prod和Val需要各自实现8个方法。
所以增加2个新的类一共需要实现25个额外的方法,额外方法的个数与新增子类的个数呈平方关系,有点不好接受。那么如何解决这个问题呢,我们看下面几种解决方法
- Non-Solution:Type Tests and Type Casts
我们在`Expr`里减少这5个方法,在Number,Sum,Prod和Val各自实现各自所需的方法。这样做就不需要Expr的子类实现多余的方法。在def eval(e:Expr):Int里我们只需要用Type Tests和Type Casts来进行实现。

这个方法的优点是不需要classficiation和accesor方法在1 2 3 4 5
def eval(e:Expr):Int = { if(e.isInstanceOf[Number]) e.asInstanceOf[Number].numValue else if(e.isInstanceOf[Sum]) eval(e.asInstanceOf[Sum].leftOp) + eval(e.asInstanceOf[Sum].rightOp) else throw new Error("Unknown expression" + e) }
Expr里,只需要将access方法在只需要的类里实现即可;缺点是low-level and potentially unsafe。因此我们把这个方法称为Non-Solution。
- 1st-Solution:Object-oriented decomposition
Object-oriented decomposition: breaks a large system down into progressively smaller classes or objects that are responsible for some part of the problem domain。
OOP decomposition看起来简单多了,如果再需要扩展1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
//OOP decomposition trait Expr{ def eval: Int } class Number(n:Int) extends Expr{ def eval: Int = n } class Sum(e1:Expr, e2:Expr) extends Expr{ def eval:Int = e1.eval + e2.eval } object ExprTest extends App{ val x = new Sum(new Number(1), new Number(2)) println(x.toString()) }
Prod和Val子类,只需要各自实现如上evalmethod即可。但是如果我们需要一个方法来展示Expr呢,比如说Showmethod,我们需要在Expr所有的子类里定义这个新方法。另外如果我们需要实现 a * b + a * c -> a * (b + c)这个提取公因式的method,我们该如何做呢。由于这个方法涉及不同的子类,因此无法通过在一个子类里的method实现,我们必须又得回到该开始的平方增加的例子(增加access method在所有子类里)。
4.2 Pattern Match 语法
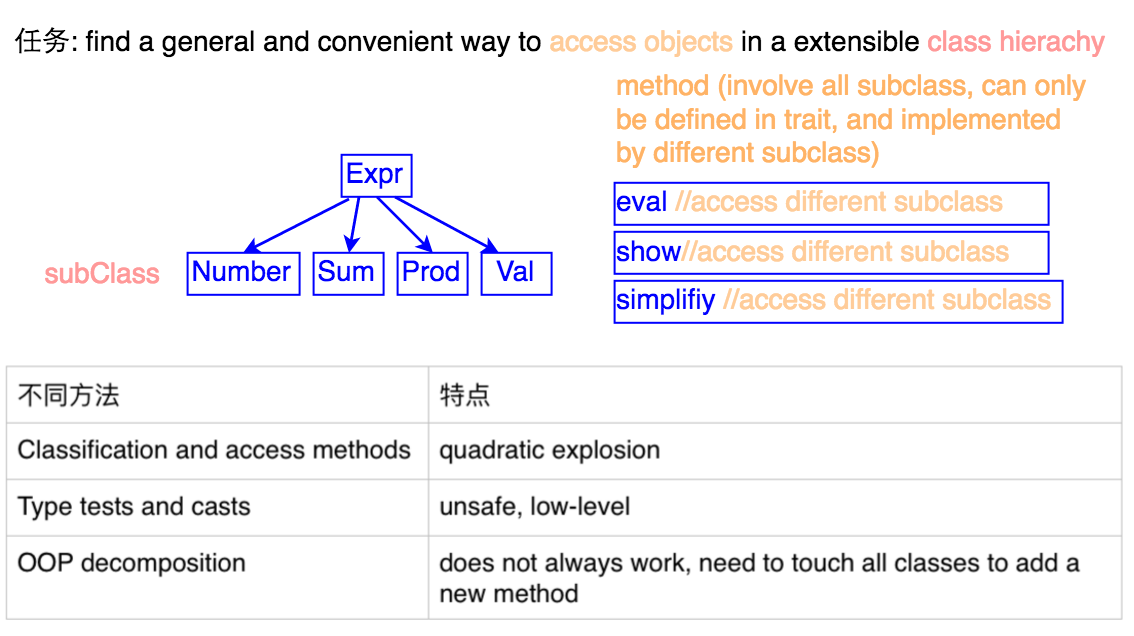
我们来对前面的问题做一个小结,我们的任务是想要同时在扩展子类和扩展接口方法(接口方法指的是适合所有子类,定义在接口里,而具体实现需要access subclass’s own method implementation,即子类方法)上获取一个普适的方便的方法:
- 第一种方法,是将子类classificatoin和子类方法全部声明在接口中,这样做的弊端是产生了很多不必要的方法,原有方法的实现和扩展类的个数呈平方关系,这还不包括扩展新的接口方法,因此这种方法效率极其低下,耦合太紧;
- 第二种non-solution,在接口方法里用type tests和type casts分别调用子类方法。这样如果扩展子类只需要在新子类中自己实现相应的接口方法调用的子类方法,然后在接口方法里增加对于这个新的子类的type tests和type casts。这样做相比于第一个方法貌似灵活了许多,但是却是low-level和unsafe的;
- 第三种方法是OOP的decomposition,这其实是我们现在对接口的最常用的方法。现在看起来理所当然的方法,但是当我们一步步从这之前走到decomposition所要比较和改进的思路不是那么容易的。OOP的decomposition即在接口里定义接口方法,然后在子类中直接实现。如果需要扩展子类,只需要在子类中实现已有的接口方法;如果需要扩展接口方法,只需要在接口里定义新接口方法,然后分别在子类里增加实现。这样我们将扩展子类和扩展接口方法解耦,使得OOP的Class有着灵活的扩展性。但是对于扩展接口方法我们能否做的更好呢?下面我们看看Pattern Match。
先上代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
object ExprTest extends App{
trait Expr
case class Number(n:Int) extends Expr
case class Sum(e1:Expr,e2:Expr) extends Expr
/* implicit define the companion factory method,Number(2) would be Number.apply(2). No need to use new Number(2) anymore
object Number{
def apply(n:Int) = new Number(n)
}
object Sum{
def apply(e1:Expr,e2:Expr) = new Sum(e1,e2)
}
*/
//pattern match
def eval(e:Expr):Int = e match{
case Number(n) => n
case Sum(e1,e2) => eval(e1) + eval(e2)
}
def show(e:Expr):String = e match{
case Number(n) => n.toString()
case Sum(e1,e2) => "( " + show(e1) + " + " + show(e2) + " )"
}
val x = Sum(Number(1), Number(2))
println(show(x))
}
我们来一一解释:
- 首先定义了一个接口 Expr,然后显示表示这个接口的子类是一个所有需要的子类的枚举,关键词是case。在Scala里这就隐式声明了各个需要子类的工厂方法,当你调用
Number(2)的时候,会被转换成Number.apply(2)(apply的实现就是new Number(n),即new了一个新的Number实例)。
2.然后在接口里直接实现了接口方法,用的就是Pattern Match。枚举分流接口方法的子类类型,这里可以看到有在Sum里有递归调用,这是函数式的体现。
- 如果我们需要扩展接口方法,比如增加一个
Show的接口方法,同样的使用Pattern Match。这样对比与OOP的decomposiont的扩展接口方法,可以看到更加简洁方便(不需要在每一个子类中分别实现接口方法)。
因此Pattern Matching可以说是函数式OOP的核心(递归调用),是对命令式OOP接口decompostion的一个提升。Pattern Matching建立在scala的trait可以有method的实现,和函数式的递归基础上。
Pattern Matching的语法如下图
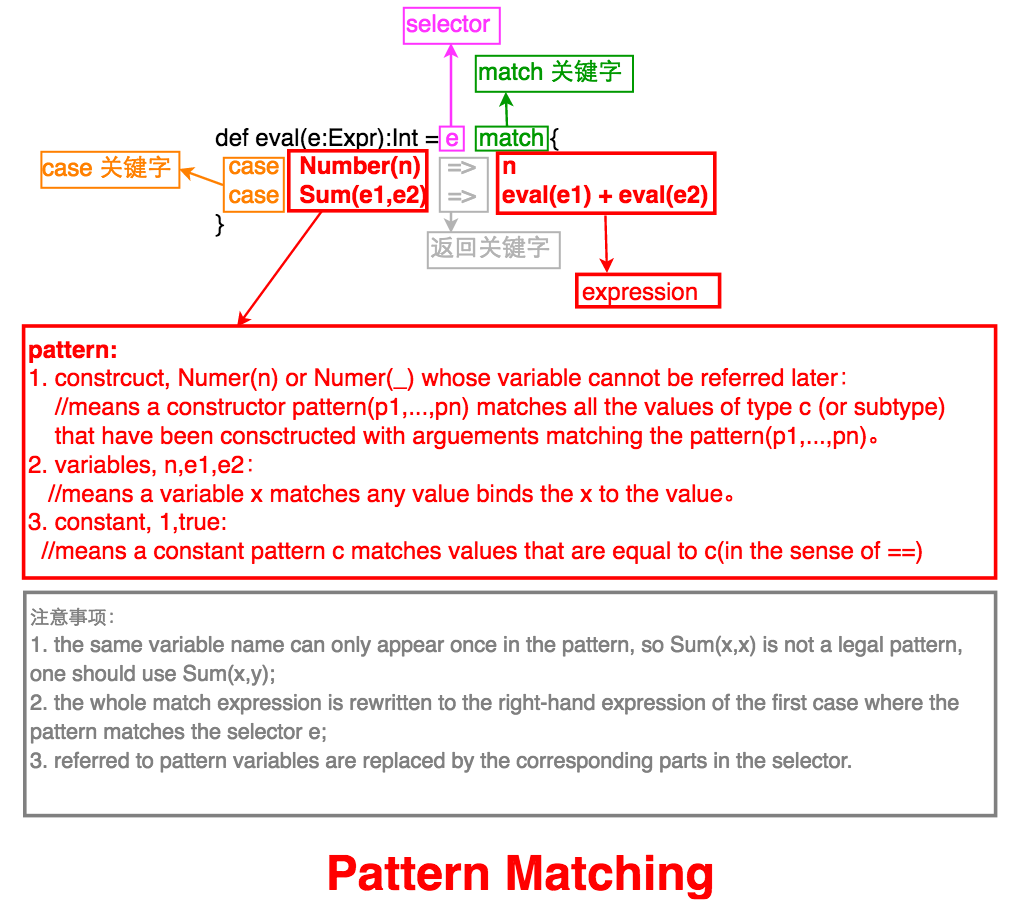
4.3 Pattern Match 例子
现在我们将上面这个例子重新改写,将pattern matching 封装在Expr里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
object ExprTest extends App {
//将pattern matching 封装在trait里
trait Expr {
//pattern match
def eval(): Int = this match {
case Number(n) => n
case Sum(e1, e2) => e1.eval + e2.eval
}
def show(e: Expr): String = e match {
case Number(n) => n.toString()
case Sum(e1, e2) => "( " + show(e1) + " + " + show(e2) + " )"
}
}
case class Number(n: Int) extends Expr
case class Sum(e1: Expr, e2: Expr) extends Expr
/* implicit define the companion factory method,Number(2) would be Number.apply(2). No need to use new Number(2) anymore
object Number{
def apply(n:Int) = new Number(n)
}
object Sum{
def apply(e1:Expr,e2:Expr) = new Sum(e1,e2)
}
*/
val x = Sum(Number(1), Number(2)).eval()
println(x)
}
这就是Expr的最终的实现形式,如果需要扩展子类和扩展接口方法,聪明的你,肯定知道怎么做了^_^。
4.4 Pattern Matching vs OOP decomposition

Pattern Maching和OOP Decompostion各有优劣,那么在我们实际编程中,该如何选择呢:
- 如果更多的是扩展子类,则用OOP Decompostion;
- 如果更多的是扩展接口方法,则用Pattern Matching
5 Assignment
本周作业是霍夫曼编码,其中的难点是如何用tuple来做pattern matching来简化实现,举个具体的例子,def decode(tree: CodeTree, bits: List[Bit]): List[Char]将整数链表转换成字母链表。用tuple只需要4个pattern。但是需要格外小心的是4个pattern的先后顺序,一个实用的经验是从一次完整的函数调用来排列case的顺序。比如这里,对于一个正常的tree:CodeTree,如果bits0是0开头,则进入左边的subtree,1开头则进入右边的subtree;如果碰到叶子节点,则将char加入到acc,然后从头开始调用tree和剩下的bits0;最后当bits0满足Nil时,返回acc。
这里请同学们思考一个问题,如果将第三个case的a改成x::xs,结果还是正确的吗?答案是不正确的,因为最后一个字母没有被加入到acc里(x::xs将Nil的情况给剔除了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/**
* This function decodes the bit sequence `bits` using the code tree `tree` and returns
* the resulting list of characters.
*/
def decode(tree: CodeTree, bits: List[Bit]): List[Char] = {
def decode0(tree0: CodeTree, bits0: List[Bit], acc: List[Char]): List[Char] = (tree0, bits0) match {
case (Fork(left, right, chars, weight), 0 :: xs) => decode0(left, xs, acc)
case (Fork(left, right, chars, weight), 1 :: xs) => decode0(right, xs, acc)
case (Leaf(char, weight), a) => decode0(tree, a, acc :+ char)
case (x, Nil) => acc
}
decode0(tree, bits, List())
}
具体代码见这里。
6 总结
当OOP遇上λ-Calculus,Scala给出了自己的实现方案:
- 万物皆类。Primitive Data,Compound Data,Primitive Procedure,Compound Procedture(Function)都是类。
- 函数式的体现不仅在于将函数也表示成类,而且在于实现Data的时候优先考虑递归和用Pattern Matching更方便的将接口实现用于扩展接口方法。当然函数式体现还体现在Data实现里的immutable特性。
最后将本节内容总结成一张图。

