
目录
1 非监督式学习
Unsupervised Learning:is the machine learning task of inferring a function to describe hidden structure from unlabeled data。换句话说,监督式学习是$\lbrace (x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), \cdots,(x^{(m)},y^{(m)}) \rbrace$中拟合;非监督式学习是$\lbrace x^{(1)}, x^{(2)}, \cdots, x^{(m)} \rbrace$中找分成几类以及如何分类。
非监督式学习方法有:聚类(Clustering),降维 (Dimensionality Reduction),异常检测(Anomaly Detection),神经网络(Neural Networks)。
本文我们着重介绍聚类(Clustering)和降维 (Dimensionality Reduction)。
1.1 聚类(Clustering): K-Means算法
聚类(Clustering):聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。
聚类的一个最为重要的算法是K-Means算法。

1.2 降维(Dimensionality Reduction):PCA算法
聚类(Clustering):在机器学习和统计学领域,降维是指在某些限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程。 降维可进一步细分为特征选择和特征检测两大方法。
降维的一个最为重要的算法是主成分分析(Principal Component Analysis,PCA)算法。

1.3 异常检测 (Anormaly Detection):高斯分布

2 作业
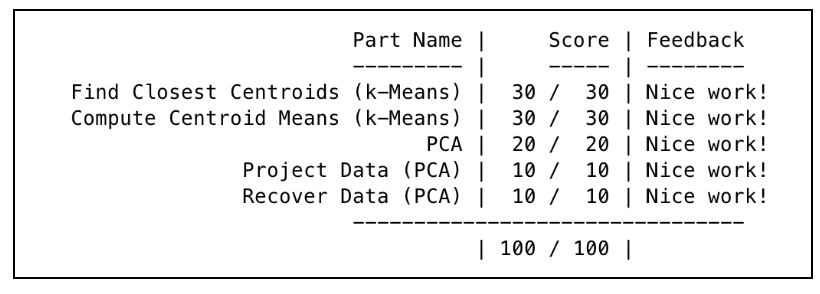
见这里。附上一张跑分图。
3 总结
本文介绍了聚类的K-means算法,降维的PCA算法和异常检测的高斯分布算法。
-
聚类的K-means算法用于将unlabel的数据归类;
-
降维的PCA算法用于数据压缩和可视化;
-
异常检测用于有大量正常数据和少量非正常数据,通过高斯分布,排除非正常数据。它不同于监督式学习的分类(通过学习大量正常和大量不正常数据)。
三者都属于非监督式学习。
