目录
本文是《Web Scraping With Python》的最后一篇笔记,我们将会介绍如何从不同的机器甚至不同的IP地址来运行我们的Web Scraper。你将会为它们带来的便利性感到惊讶。
1 为什么使用远程服务器
如果我们想把网络程序展现给其他用户,则让其运行在一个远程服务器是我们的一个选择。但是如果是对于我们自己的Web Scraper,为什么需要运行在远程服务器呢。答案通常是两个:
-
使用不同的IP地址。
-
提高性能和灵活性;
1.1 防止IP地址被封
当写Web Scraper的时候,有一点经验是:什么都能被伪装。从你不拥有的邮箱地址发邮箱,到从命令栏模仿鼠标移动,到通过发送虚假网站流量来刺激下网站管理员等。
但是有一点不能伪装的是你的IP地址。因为如果你的IP地址是假的,那么你就收取不到response。
大部分情况下网站反爬虫的努力在与区别人类和机器。而封掉IP地址有点像农民放弃喷洒农药来消灭害虫转而焚烧农田。会带来以下副作用。
-
IP address访问表维护起来比较困难。
-
如果检查一个IP address是不是存在IP访问表里,会增加服务器对每一个网络请求的处理时间。系统可以将属于某个范围的IP地址都从一个访问表都移除来加快处理时间,但是这样会引起额外的问题。
-
会禁止某些潜在的真实访问者。某个单独IP address被封,可能会导致相邻的同一个公司或者部门的IP地址都被封。
虽然有这些副作用,但是封IP还是一个非常常见的反爬虫方法。
1.2 便携性和可扩展性
有些时候你的个人电脑运行Web Scraper会有点吃力。你可能不会一次性大量访问某个网站,但是你会访问多个网站。而且更多的时候你想解放你的电脑做些更重要的事情,比如玩个魔兽世界,沙滩排球啊啥的。而且有些情况下你的电脑处理能力不够的话的话,你可以使用Amazon的大型计算机,如果还满足不了,可以使用distributed computing。你可以复制google的搜索,但是很少有人可以复制google的搜索规模。
所以使用如何将你的程序运行在远程服务器可以大大提高你电脑的便携性和可扩展性,并且你或许会对当今世界的电脑的运算能力吃惊。
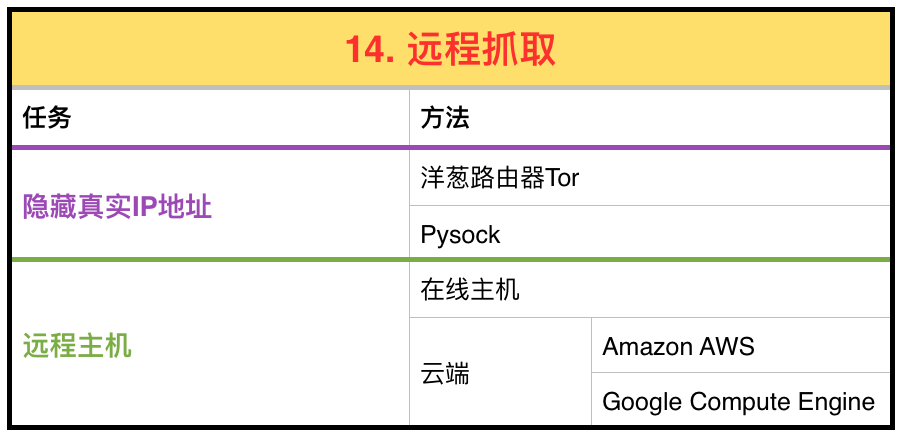
2 Tor and Pysocks
Tor是一个匿名浏览网页的程序。
洋葱路由器(Tor,The Onion Router network):是实现匿名通信的自由软件. Tor将网络传输通过由七千多个继电器的网络经复杂的传输来实现网络传输的匿名性。
Pysock可以和Tor结合一起使用。
Pysock:可以在不同代理服务器进行路由的Python module。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import socks
import socket
from urllib.request import urlopen
from selenium import webdriver
#method 1
socks.set_default_proxy(socks.SOCKS5,"localhost",9150)
socket.socket = socks.socksocket
print(urlopen("http://icanhazip.com").read())
#method 2 combine with selenium
service_args = ['--proxy=localhost:9150', '--proxy-type=socks5', ]
driver = webdriver.PhantomJS(executable_path='/Applications/phantomjs-2.1.1-macosx 2/bin/phantomJS',service_args=service_args)
driver.get("http://icanhazip.com")
print(driver.page_source)
driver.close()
#output:
#176.126.252.11 (这个地址是fake IP)
3 远程主机
虽然你用信用开购买远程主机就使得你Web Scraper的匿名访问完全失效了。但是远程主机可以大大提高你的运行性能,因为不仅你可以获得比你拥有的机器更高的性能,而且因为不需要经过tor来层层包裹你的原始IP地址。
3.1 从在线主机账号运行
略。
3.2 从云端运行
Amazon AWS和 Google Compute Engine都提供云端服务,其价格和你购买一台电脑的平均价格基本一致,但是你不用再担心如何维护机器了。
相应有两本书是具体介绍Amazon AWS和Google Compute Engine。
4 下一步
互联网一直在飞速发展。但是唯一不变的解决问题的根本方法,当我们在未来碰到Web Scraping的项目时,请问自己以下几个问题:
-
我要解决的具体是什么问题。
-
什么数据能帮助我实现解决。
-
网站是如何展示这些数据的,我该如何定位这些数据。
-
我该如何获取这些数据。
-
需要对这些数据进行处理或者分析吗。
-
如何可以让我的项目运行更快更健壮。
-
我该如何将不同的模块结合一起使用。
当你面对的是一个自动数据收集的问题时,基本上都是可以解决的。你只需要记住互联网是一个巨大的API,但是它的用户界面稍显糟糕而已,需要我们自己去清理。
5 总结
本文总结成下图。
6 本系列总结
6.1 Web Scraping Final Summary

6.2 Web Scraping Final Summary with Details