
目录
1. 介绍
2. Stream(流)
2.1 问题的由来
我们首先思考下面一个问题,如何获取1000后面第二个质数?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def isPrime(n:Int):Boolean = (2 until n).forall(x=>n%x!=0) //isPrime function
//solution 1
(1000 to 10000).filter(isPrime)(1) //Int = 1013
//solution 2
def nthPrime(begin:Int,n:Int):Int = {
if(n==0) {
if (isPrime(begin)) begin
else nthPrime(begin+1, n)
}else{
if (isPrime(begin)) nthPrime(begin+1,n-1)
else nthPrime(begin+1,n)
}
}
nthPrime(1000,2) //Int = 1013
上例中,第一种方法,我们选取了一个上界10000,确保1000后面第二个质数介于1000和10000之间,然后过滤出在此区间所有的质数,最后取index为1的那个;第二种方法是用递归函数实现,比第一种要快(不需要计算多个质数,只需计算到第二个就停止),但是写起来略显麻烦。那么能能有一种解决方法把这两种的优势结合起来呢?也就是说同时有第一种的简洁和第二种的高效?
答案是可以的,我们用一种叫做Stream(流)的数据结构
1
2
3
def isPrime(n:Int):Boolean = (2 until n).forall(x=>n%x!=0) //isPrime function
(1000 to 10000).toStream.filter(isPrime)(1) //Int = 1013
将Range先转换成Stream的好处是只需要计算到第二个质数便可以,不用计算所有1000-10000的所有的质数。是不是很神奇呢?
2.2 流的语法和本质
lazy evaluation的理论基础:函数式编程的输出只和输入有关,与时间没有关系,因此可以将函数的调用推迟到需要的时候。这是命令式编程所不具备的。
这究竟是怎么实现的呢?细细回想,不知道同学们还记不记得本系列第一篇文章)中对于赋值有两种方式,一种是call by value(CBV),另一种是call by name(CBN)。没错,聪明的你一定想到Stream的实现和CBN有关。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
trait Stream[+A] extends Seq[A]{
def isEmpty:Boolean
def head:A
def taol:Stream[A]
}
object Stream{
def cons[T](hd:T,tl:=>Stream[T]) = new Stream[T]{
def isEmpty = false
def head = head
lazy val tail = tl
}
val empty = new Stream[Nothing]{
def isEmpty = true
def head = throw new NoSuchElmentException("empty.head")
def tail = throw new NoSuchElmentException("empty.tail")
}
}
可以看到,Stream的定义和实现大部分和List相近,List的API,Stream都可以直接使用。
需要注意的是若要在一个xStream后加xs Stream来构建新的Stream,需要用到x#::xs的语法(这和List的x::xs语法略有不同)
但是有一个地方是Stream的核心,那就是tl的调用是CBV,即=>。因此,在Stream实例调用tail之前,tail就是一个指向一段代码的指针而已。
在某些场景下,我们不仅需要CBN,而且需要指针指向的代码只运行一次,存储结果。这就需要同时结合=>和lazy val
Lazy Evaluation:do things as late as possible and never do it twice。
我们举一个栗子。
1
2
3
4
5
6
7
8
9
def expr{
val x = {print("x");1}
lazy val y = {print("y");2}
def z = {print("z");3}
z + y + x + z + y + x
}
expr
这段代码的输出是什么呢?答案是”xzyz”。因为val在定义时已经执行,lazy val在调用时才执行且将结果保存,以后再调用就直接取结果,def在调用时才执行,而且每调用一次执行一次。
2.3 流的应用
由于流的“lazy evaluation” = “lazy val” + “=>”的性质,它在构建无限序列方面打开了一扇崭新的大门。为什么这么说呢,请看下面这个栗子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//定义了一个无限整数序列,从n开始。Stream保证这个递归函数不会陷入死循环。
def from(n: Int): Stream[Int] = n #:: from(n + 1) Stream[Int]
//nat 表示所有自然数(从0开始),由于用val,因此直接将0代入from算得结果为//Stream(0, ?)
val nat: Stream[Int] = from(0) //Stream(0, ?)
//取前100个自然数然后乘以4。结果是Stream(0, ?)
val n100s = nat.map(_*4).take(100) //Stream(0, ?)
//将n100s转换成List,这个时候,Stream的tail被调用,执行代码。
n100s.toList //> res7: List[Int] = List(0, 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52,
//| 68, 372, 376, 380, 384, 388, 392, 396)
//用 sieve Eratosthenes 方法计算质数
def n2s = from(2) //Stream[Int]
def sieve(start:Stream[Int]):Stream[Int] =
start.head #::sieve(start.tail.filter(_%start.head !=0))
//> sieve: (start: Stream[Int])Stream[Int]
sieve(n2s).take(100).toList //> res8: List[Int] = List(2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43,
//| 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 1
//| 31, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 2
//| 11, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 2
//| 93, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 3
//| 89, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 4
//| 79, 487, 491, 499, 503, 509, 521, 523, 541)
Stream的这种表示无限序列的特性可以用在整数序列,自然数序列,质数序列函数上,他们的定义非常学术化,和数学公式一样严谨。但是由于Stream的lazy evaluation特性,又不会陷入死循环,只有在调用到Stream的tail的时候,才会执行相应代码。
2.4. Water Pouring Problem
这里我们将Stream用于解决著名的Water Pouring Prolem。
Water Pouring Prolem:给定一组指定整数容量的容器(里面没有刻度)(x1,…xn),和一个无限自来水的源头以及一个无限容量的水盆,求如何获取某一整数容量的自来水。举个例子,如果有4L和7L两个水桶(分别标记为0号和1号水桶),要获取6L的水,可以1号倒满7L,分给0号4L,然后0号倒空4L,1号再倒3L给0号,接着倒满1号7L,然后1号倒满0号(已有3L只需1L),最后1号里剩下的就是6L。
如何解决这个问题呢,先上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
class Pouring(capacity: Vector[Int]) {
//states
type State = Vector[Int]
val initialState = capacity.map(_ => 0)
//Moves
trait Move {
def change(state: State): State
}
case class Empty(glass: Int) extends Move {
def change(state: State): State = state.updated(glass, 0)
}
case class Fill(glass: Int) extends Move {
def change(state: State): State = state.updated(glass, capacity(glass))
}
case class Pour(from: Int, to: Int) extends Move {
def change(state: State): State = {
val amount: Int = state(from).min(capacity(to) - state(to))
state.updated(from, state(from) - amount).updated(to, state(to) + amount)
}
}
val glasses = 0 until capacity.length
val moves = (
(for (g <- glasses) yield Empty(g)) ++
(for (g <- glasses) yield Fill(g)) ++
(for (from <- glasses; to <- glasses if to != from) yield Pour(from, to)))
//class Path, sequence of moves, it also has the end state
class Path(history: List[Move],val endState:State) {
def extend(move: Move): Path = new Path(move :: history,move.change(endState))
override def toString() = history.reverse.mkString(" ") + "--->" + endState
}
val initialPath:Path = new Path(Nil,initialState)
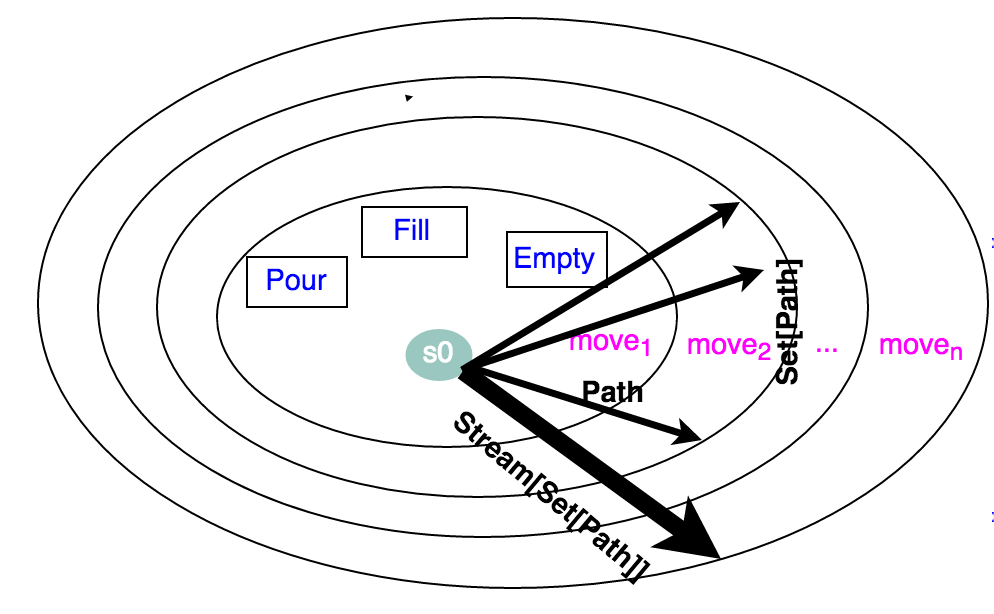
def from(pathSet:Set[Path],exploredState:Set[State]): Stream[Set[Path]] = {
if (pathSet.isEmpty) Stream.empty
else {
val nextPathSet: Set[Path] = (
for (
path<- pathSet;
nextPath<- moves.map(path.extend)
if !(exploredState.contains(nextPath.endState))
) yield nextPath).toSet
pathSet #:: from(nextPathSet, (exploredState ++ nextPathSet.map(_.endState)))
}
}
val pathSets = from(Set(initialPath),Set(initialState))
def solution(target: Int): Stream[Path] = {
(
for (
pathSet <- pathSets;
path <- pathSet if path.endState.contains(target)
) yield path).toStream
}
}
object testPouring {
println("hello world2") //> hello world2
val pouring = new Pouring(Vector(4,9)) //> pouring : week7.Pouring = week7.Pouring@7ca48474
pouring.moves //> res0: scala.collection.immutable.IndexedSeq[Product with Serializable with w
//| eek7.testPouring.pouring.Move] = Vector(Empty(0), Empty(1), Fill(0), Fill(1)
//| , Pour(0,1), Pour(1,0))
pouring.solution(6).take(2).toList //> res1: List[week7.testPouring.pouring.Path] = List(Fill(1) Pour(1,0) Empty(0)
//| Pour(1,0) Empty(0) Pour(1,0) Fill(1) Pour(1,0)--->Vector(4, 6), Fill(1) Pou
//| r(1,0) Empty(0) Pour(1,0) Empty(0) Pour(1,0) Fill(1) Pour(1,0) Empty(0)--->V
//| ector(0, 6))
}
我们来一步步解释:
-
我们有一个Pouring(capacity: Vector[Int])类,构造器的输入时
Vector[Int],index表示水桶的编号,里面的值表示水桶的总容量。Pouring有一个field是state: Vector[Int]表示当下各个水桶的现有水量。还有一个trait Move封装了三种对于水桶的操作,分别是Fill(glass:Int),Empty(glass:Int)和Pour(from:Int,to:Int)。这三种操作都可以改变state,各自的实现在代码里,需要注意的是Pour(from:Int,to:Int)的实现要考虑to水桶的剩余容量和from水桶的现有容量的关系(取其中小的一个)。 -
在有了基本的state和操作
trait Move类后,我们要如何组织我们的业务逻辑找到最终的答案呢。我们定义一个类Path,它表示Move的序列,即List[Move],以及最后状态的合集,Set[State]。既然它是Move的序列,那么可以在当前Path基础上(n个Move)增加一个Move生成(n+1个Move的Path),这也就是extend方法。 -
对于无限序列
from(initial:Set[Path]):Stream[Set[Path]],输入一个开始的Set[path],输出一个无限的Stream[Set[Path]序列。这类似之前的自然数序列,输入一个n,输出所有n后的整数。 -
还有一点需要注意的是性能问题,对于之前探索过的
Set[State],Pathextend后要过滤掉回到之前State的Path。
3. assignment
4. 总结
最后用一张图对本系列做一个总结:

