目录
- 1 Character Classes
- 2 Anchors
- 3 Escaped Characters
- 4 Groups & Lookaround
- 5 Quantifiers & Alternation
- 6 总结
- 7 参考资料
A popular quote by Jamie Zawinski: “Let’s say you have a problem, and you decide to solve it with regular expressions. Well, now you have two problems.”
正则表达式(Regular Expression):匹配一系列匹配某个句法规则的字符串。每一个正则表达式里的字符(Token)要么是元字符(metacharacter),要么是字面字符(with its literal meaning)。它们一起组成了匹配的规则。
正则表达式的基本概念分为:
- 字符类;
- 锚点(或者称为定位点);
- 转义序列;
- 组与环顾;
- 量词与替代。
以下内容来自于regexr的总结。
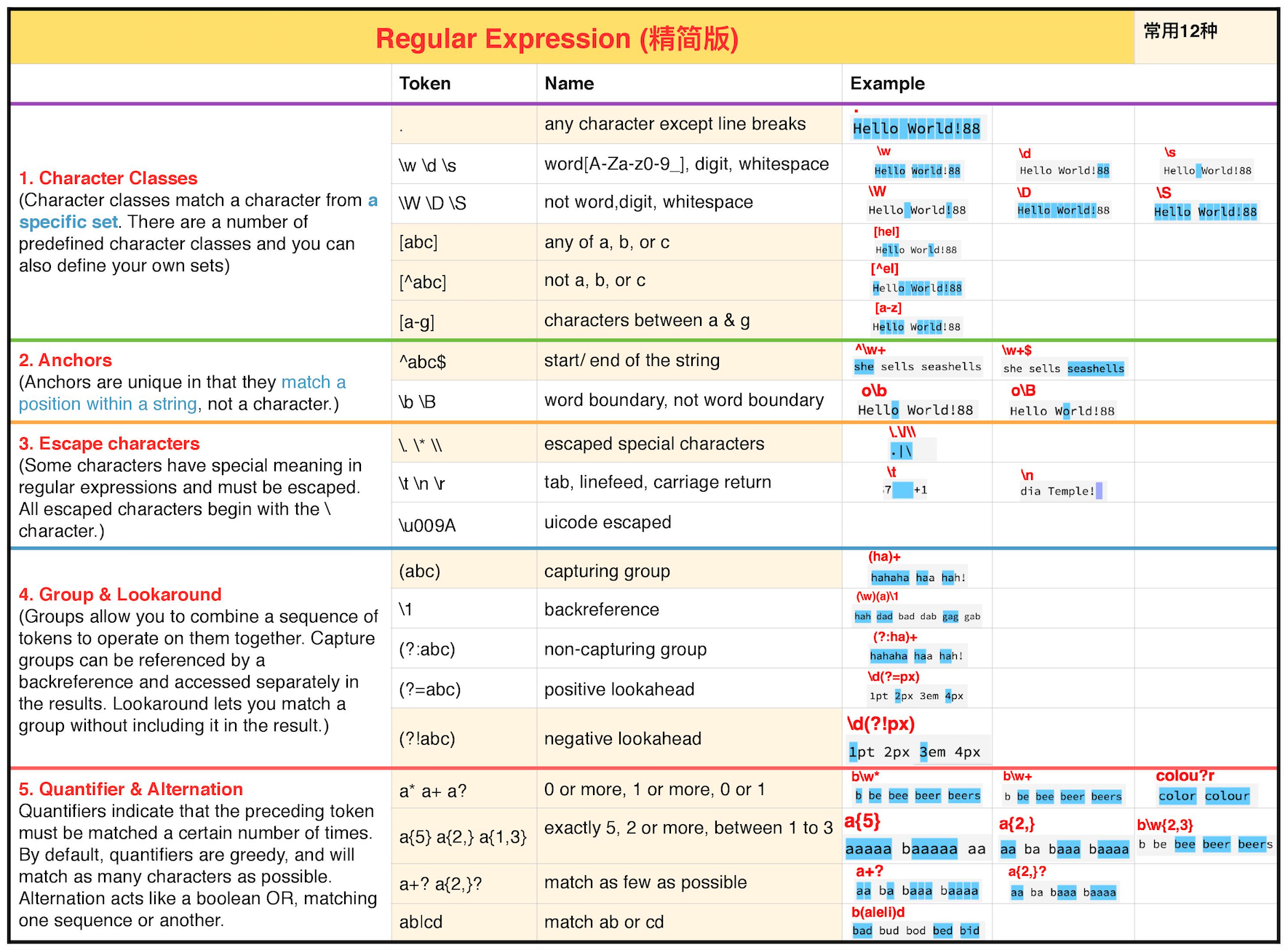
1 Character Classes
字符类Token(Character Classes):匹配某一Token表示的集合(set)里的所有字符元素。
常用的有6种:
-
.表示任意字符,但不包括换行。 -
\w\d\s分别表示word(26个大小写字母加数字加下划线即[A-Za-z0-9_]),digit[0-9],whitespace。 -
\W\D\S分别表示非word,非digit和非whitespace。 -
[abc]表示a或b或c。 -
[^abc]表示非a或非b或非c -
[a-g]表示a到g
2 Anchors
定位符Token(Anchors):匹配字符串里的位置,而不是字符。
主要有两种:
-
^表示字符串开头;$表示字符串结尾。 -
\b表示字符串边界;\B表示字符串非边界。
3 Escaped Characters
转义序列Token(Escaped Characters):以
\作为转义字符,将有特殊含义的字符转换成其字面值。
主要有两种:
-
\.表示.;\|表示; \\表示]\。 \t表示tab;\n表示换行;\r表示回车。关于换行和回车的区别见这里,简单来说就是以前在打印的时候回车表示打印头移到最左边,换行表示打印纸往上移一行。在现在的计算机里,两者的存在只是延续了传统,很多时候换行和回车都合并为换行了。
4 Groups & Lookaround
组合Token(Groups):表示将多个字符当做一个整体一起处理。
主要包括3种:
-
(abc)表示abc为一个整体。 -
\1表示反向引用第1个group(其中1可以改成任意数字)。 -
(?:abc)表示不将abc为一个整体;
环顾(Lookaround):表示将组合作为匹配条件,但是不包括在结果里。
主要有两种:
-
(?=abc)表示匹配组合的abc,但是结果里不将其包括。 -
(?!=abc)表示匹配组合的非abc,但是结果里不将其包括。
5 Quantifiers & Alternation
量词Token(Quantifiers):表示之前的字符出现的次数。
主要有3种:
-
a*表示出现≥0次a;a+表示出现≥1次a;a?表示出现0或1次a。 -
a{5}表示出现5次a;a{2,}表示出现≥2次a;a{1,3}表示出现1至3次a。 -
a+?表示出现≥0次a的最少个数,即0个a;a{2,}?表示出现≥2次a的最少个数,即2个a。
替代Token(Alternation):表示或。
1种:
a|b表示a或者b。
6 总结
最后用一张图对Regular Expression进行总结。