
目录
1 What is Web Scraping
我们要想了解Web Scraping是什么,以及它处于网络的什么位置,那就不可避免的要先介绍什么是网络。
1.1 What is Network

Network是一个较为复杂的概念,上图是用Four Layer Reference Model来表示Network。首先是4层Layer,分别是Application Layer,Transport Layer, Internet Layer, Link Layer,每一层layer有自己的多种协议。
-
Application Layer:包括HTTP协议(Hypertext Transfer Protocol,是万维网,即www,传输数据的基础),SMTP协议(Simple Mail Transfer Protocol,电子邮件传输协议),RTP协议(Real-time transport protocal,用于通过IP来传输音频和视频)和DNS协议(域名解析协议,即网址和IP一一对应的解析协议)。
-
Transport Layer:包括TCP协议(Transmission Control Protocol,建立在IP协议之上,将IP协议的数据传输单位Packet,提升至Segment,即特定序列的Packet)。
-
Internet Layer:IP协议(Internet protocol,是在protocol stack(协议栈)中间连接物理层和软件层的协议,是最窄的腰部,但是确是最重要的必经的协议)。
-
Link Layer: 包括Ethernet,3G,802.11,Cable,DSL等网络连接协议。
1.2 What is Socket
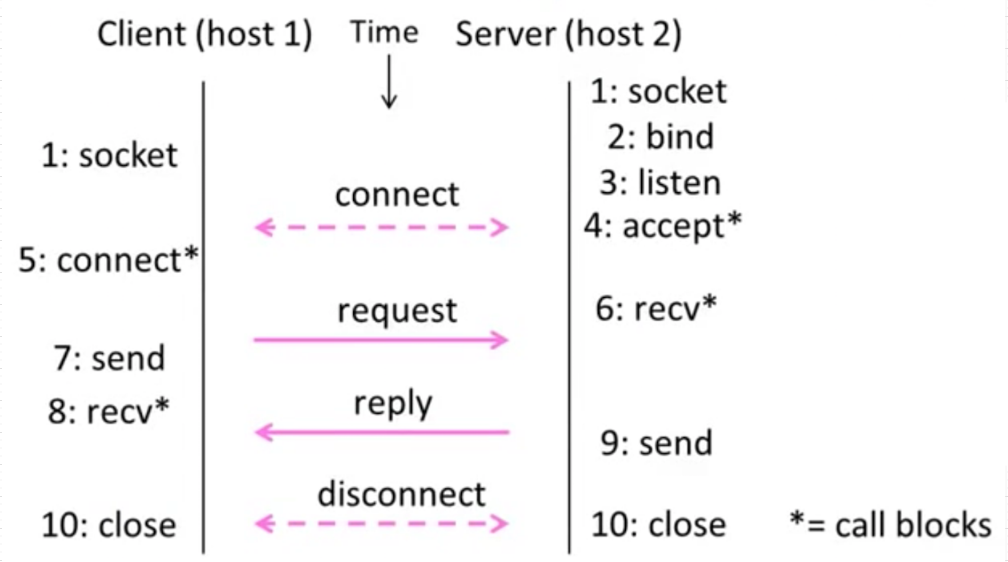
在Four Layer Reference Model中,更为准确地说,Transport Layer, Internet Layer, Link Layer属于Network,而Application Layer是属于App。因此连接Network和App的界面的框架称之为Socket。Socket的客户端和服务端需要进行一系列顺序对话才能完成数据的传输,如下图所示。关于Socket的具体介绍,请参见网络系列的博文。
1.3 What is Network Data Type
-
HTML:Hyper Text Markup Language,超文本标记语言。“超文本”就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。
-
XML:Extensible Markup Language,可扩展标记语言。XML用于传输数据,html用于展示数据。
-
JSON:JavaScript Object Notation,一种轻量级的数据交换格式。相比于XML,JSON通常解析速度提高30%,占用空间少30%,但是前者标记更完全。
-
CSS:Cascading Style Sheets,层叠样式表。用于规定html的展示形式。
1.4 What is Browser
Web Browser (commonly referred to as a browser): a software application, focus on HTML formatting, CSS styling, JavaScript execution, XML or JSON serialization and de-serialization via World Wide Web, for information(located by a Uniform Resource Identifier (URI/URL)) retriving and presention.
1.5 What is and Why Web Scraping
Web Scraping:extracting information from websites other than Browser.
Why web scraping:
-
Browser不能有效收集信息,太分散;
-
网站API没有,或者不符合你的要求,需要自己写一个网络爬虫来收集信息;
-
市场预测,机器语言翻译,等等。
1.6 What is BeautifulSoup
Beautiful Soup: a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work。
Beautiful Soup是Python语言下Web Scraping的一个最为重要和流行的框架,用于访问HTML和XML文件。
2 urllib
urllib:a Python module that provides a simple interface for network resource access, 例如HTML files, image fiels, or any other file stream. It is An abstraction and simplification over Socket.
It has 4 submodules and the urlopen method in urllib.request takes string or request object and return http.client.HTTPResponse object for HTTP and HTTPs URLs.

1
2
3
4
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html") #获取html文件句柄
print(html.read()) #读取html文件内容并打印
3 BeautifulSoup
我们用一个小程序作为我们第一个网络爬虫,来感受下BeautifulSoup。
1
2
3
4
5
6
7
from urllib.request import urlopen
from bs4 import BeautifulSoup
htmlHandler = urlopen("http://pythonscraping.com/pages/page1.html") #获取html文件句柄
bsObj = BeautifulSoup(htmlHandler.read(),"html.parser") #读取html文件内容,然后实例化BeautifulSoup
print(bsObj.h1) #打印 h1 tag, 完整的是bsObj.html.body.h1
#输出: <h1>An Interesting Title</h1>
健壮性:由于网络会出现各种不确定性,如连接断开,服务端关闭,服务端html目录错误找不到等,都会产生异常。因此我们要周到的考虑异常的处理,上面code的健壮性完善后如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None #若HTTPResponse为HTTPError,处理异常
try:
bsObj = BeautifulSoup(html.read(), "html.parser")
title = bsObj.h1 #若h1不存在,则title为None;若用title,则返回AttributeError。这里统一处理
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title == None: #check title是不是None,再继续
print("title couldn't be found")
else:
print(title)
4 总结
本文作为Web Scraping系列的第一篇文章,从Big Picture上介绍了Web Scraping处于Network的什么位置. 在此基础上,我们介绍了用Python进行WebScraping的两个重要Module:
- urllib,作为Socket的升级版,将网络请求和数据的接受和发送简化为几行代码。
- BeautifulSoup,将html文件和xml文件转换为Python object(这里我们刚接触到的是BeautifulSoup object)来进行方面快速强大的数据访问。
下图是对本文的总结。

关于BeautifulSoup的详细介绍,请看下篇文章。
